This chapter introduces the API you need to load processes and execute them. For more detail on how to define the processes themselves, check out the chapter on BPMN 2.0.
To interact with the process engine (for example, to start a process), you need to set up a session. This session will be used to communicate with the process engine. A session needs to have a reference to a knowledge base, which contains a reference to all the relevant process definitions. This knowledge base is used to look up the process definitions whenever necessary. To create a session, you first need to create a knowledge base, load all the necessary process definitions (this can be from various sources, like from classpath, file system or process repository) and then instantiate a session.
Once you have set up a session, you can use it to start executing processes. Whenever a process is started, a new process instance is created (for that process definition) that maintains the state of that specific instance of the process.
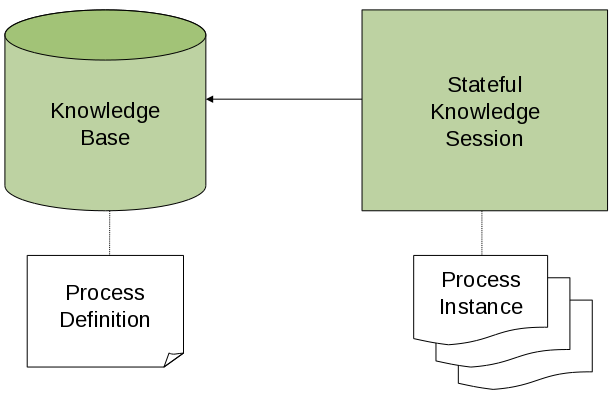
For example, imagine you are writing an application to process sales orders. You could then define one or more process definitions that define how the order should be processed. When starting up your application, you first need to create a knowledge base that contains those process definitions. You can then create a session based on this knowledge base so that, whenever a new sales order comes in, a new process instance is started for that sales order. That process instance contains the state of the process for that specific sales request.
A knowledge base can be shared across sessions and usually is only created once, at the start of the application (as creating a knowledge base can be rather heavy-weight as it involves parsing and compiling the process definitions). Knowledge bases can be dynamically changed (so you can add or remove processes at runtime).
Sessions can be created based on a knowledge base and are used to execute processes and interact with the engine. You can create as many independent session as you need and creating a session is considered relatively lightweight. How many sessions you create is up to you. In general, most simple cases start out with creating one session that is then called from various places in your application. You could decide to create multiple sessions if for example you want to have multiple independent processing units (for example, if you want all processes from one customer to be completely independent from processes for another customer, you could create an independent session for each customer) or if you need multiple sessions for scalability reasons. If you don't know what to do, simply start by having one knowledge base that contains all your process definitions and create one session that you then use to execute all your processes.
The jBPM project has a clear separation between the API the users should be interacting with and the actual implementation classes. The public API exposes most of the features we believe "normal" users can safely use and should remain rather stable across releases. Expert users can still access internal classes but should be aware that they should know what they are doing and that the internal API might still change in the future.
As explained above, the jBPM API should thus be used to (1) create a knowledge base that contains your process definitions, and to (2) create a session to start new process instances, signal existing ones, register listeners, etc.
The jBPM API allows you to first create a knowledge base. This knowledge base should include all your process definitions that might need to be executed by that session. To create a knowledge base, use a KieHelper to load processes from various resources (for example from the classpath or from the file system), and then create a new knowledge base from that helper. The following code snippet shows how to create a knowledge base consisting of only one process definition (using in this case a resource from the classpath).
KieHelper kieHelper = new KieHelper();
KieBase kieBase = kieHelper
.addResource(ResourceFactory.newClassPathResource("MyProcess.bpmn"))
.build();
The ResourceFactory has similar methods to load files from file system, from URL, InputStream, Reader, etc.
This is considered manual creation of knowledge base and while it is simple it is not recommended for real application development but more for try outs. Following you'll find recommended and much more powerful way of building knowledge base, knowledge session and more - RuntimeManager.
Once you've loaded your knowledge base, you should create a session to interact with the engine. This session can then be used to start new processes, signal events, etc. The following code snippet shows how easy it is to create a session based on the previously created knowledge base, and to start a process (by id).
KieSession ksession = kbase.newKieSession();
ProcessInstance processInstance = ksession.startProcess("com.sample.MyProcess");
The ProcessRuntime interface defines all the session methods
for interacting with processes, as shown below.
/**
* Start a new process instance. The process (definition) that should
* be used is referenced by the given process id.
*
* @param processId The id of the process that should be started
* @return the ProcessInstance that represents the instance of the process that was started
*/
ProcessInstance startProcess(String processId);
/**
* Start a new process instance. The process (definition) that should
* be used is referenced by the given process id. Parameters can be passed
* to the process instance (as name-value pairs), and these will be set
* as variables of the process instance.
*
* @param processId the id of the process that should be started
* @param parameters the process variables that should be set when starting the process instance
* @return the ProcessInstance that represents the instance of the process that was started
*/
ProcessInstance startProcess(String processId,
Map<String, Object> parameters);
/**
* Signals the engine that an event has occurred. The type parameter defines
* which type of event and the event parameter can contain additional information
* related to the event. All process instances that are listening to this type
* of (external) event will be notified. For performance reasons, this type of event
* signaling should only be used if one process instance should be able to notify
* other process instances. For internal event within one process instance, use the
* signalEvent method that also include the processInstanceId of the process instance
* in question.
*
* @param type the type of event
* @param event the data associated with this event
*/
void signalEvent(String type,
Object event);
/**
* Signals the process instance that an event has occurred. The type parameter defines
* which type of event and the event parameter can contain additional information
* related to the event. All node instances inside the given process instance that
* are listening to this type of (internal) event will be notified. Note that the event
* will only be processed inside the given process instance. All other process instances
* waiting for this type of event will not be notified.
*
* @param type the type of event
* @param event the data associated with this event
* @param processInstanceId the id of the process instance that should be signaled
*/
void signalEvent(String type,
Object event,
long processInstanceId);
/**
* Returns a collection of currently active process instances. Note that only process
* instances that are currently loaded and active inside the engine will be returned.
* When using persistence, it is likely not all running process instances will be loaded
* as their state will be stored persistently. It is recommended not to use this
* method to collect information about the state of your process instances but to use
* a history log for that purpose.
*
* @return a collection of process instances currently active in the session
*/
Collection<ProcessInstance> getProcessInstances();
/**
* Returns the process instance with the given id. Note that only active process instances
* will be returned. If a process instance has been completed already, this method will return
* null.
*
* @param id the id of the process instance
* @return the process instance with the given id or null if it cannot be found
*/
ProcessInstance getProcessInstance(long processInstanceId);
/**
* Aborts the process instance with the given id. If the process instance has been completed
* (or aborted), or the process instance cannot be found, this method will throw an
* IllegalArgumentException.
*
* @param id the id of the process instance
*/
void abortProcessInstance(long processInstanceId);
/**
* Returns the WorkItemManager related to this session. This can be used to
* register new WorkItemHandlers or to complete (or abort) WorkItems.
*
* @return the WorkItemManager related to this session
*/
WorkItemManager getWorkItemManager();
The session provides methods for registering and removing listeners.
A ProcessEventListener can be used to listen to process-related events,
like starting or completing a process, entering and leaving a node, etc. Below,
the different methods of the ProcessEventListener class are shown.
An event object provides access to related information, like the process instance
and node instance linked to the event. You can use this API to register your own
event listeners.
public interface ProcessEventListener {
void beforeProcessStarted( ProcessStartedEvent event );
void afterProcessStarted( ProcessStartedEvent event );
void beforeProcessCompleted( ProcessCompletedEvent event );
void afterProcessCompleted( ProcessCompletedEvent event );
void beforeNodeTriggered( ProcessNodeTriggeredEvent event );
void afterNodeTriggered( ProcessNodeTriggeredEvent event );
void beforeNodeLeft( ProcessNodeLeftEvent event );
void afterNodeLeft( ProcessNodeLeftEvent event );
void beforeVariableChanged(ProcessVariableChangedEvent event);
void afterVariableChanged(ProcessVariableChangedEvent event);
}A note about before and after events: these events typically act like a stack, which means that any events that occur as a direct result of the previous event, will occur between the before and the after of that event. For example, if a subsequent node is triggered as result of leaving a node, the node triggered events will occur inbetween the beforeNodeLeftEvent and the afterNodeLeftEvent of the node that is left (as the triggering of the second node is a direct result of leaving the first node). Doing that allows us to derive cause relationships between events more easily. Similarly, all node triggered and node left events that are the direct result of starting a process will occur between the beforeProcessStarted and afterProcessStarted events. In general, if you just want to be notified when a particular event occurs, you should be looking at the before events only (as they occur immediately before the event actually occurs). When only looking at the after events, one might get the impression that the events are fired in the wrong order, but because the after events are triggered as a stack (after events will only fire when all events that were triggered as a result of this event have already fired). After events should only be used if you want to make sure that all processing related to this has ended (for example, when you want to be notified when starting of a particular process instance has ended.
Also note that not all nodes always generate node triggered and/or node left events. Depending on the type of node, some nodes might only generate node left events, others might only generate node triggered events. Catching intermediate events for example are not generating triggered events (they are only generating left events, as they are not really triggered by another node, rather activated from outside). Similarly, throwing intermediate events are not generating left events (they are only generating triggered events, as they are not really left, as they have no outgoing connection).
jBPM out-of-the-box provides a listener that can be used to create an audit log (either to the console or the a file on the file system). This audit log contains all the different events that occurred at runtime so it's easy to figure out what happened. Note that these loggers should only be used for debugging purposes. The following logger implementations are supported by default:
Console logger: This logger writes out all the events to the console.
File logger: This logger writes out all the events to a file using an XML representation. This log file might then be used in the IDE to generate a tree-based visualization of the events that occurred during execution.
Threaded file logger: Because a file logger writes the events to disk only when closing the logger or when the number of events in the logger reaches a predefined level, it cannot be used when debugging processes at runtime. A threaded file logger writes the events to a file after a specified time interval, making it possible to use the logger to visualize the progress in realtime, while debugging processes.
The KieServices lets you add a KieRuntimeLogger to
your session, as shown below. When creating a console logger, the knowledge session
for which the logger needs to be created must be passed as an argument. The file
logger also requires the name of the log file to be created, and the threaded file
logger requires the interval (in milliseconds) after which the events should be saved.
You should always close the logger at the end of your application.
import org.kie.api.KieServices;
import org.kie.api.logger.KieRuntimeLogger;
...
KieRuntimeLogger logger = KieServices.Factory.get().getLoggers().newFileLogger(ksession, "test");
// add invocations to the process engine here,
// e.g. ksession.startProcess(processId);
...
logger.close();The log file that is created by the file-based loggers contains an XML-based overview of all the events that occurred at runtime. It can be opened in Eclipse, using the Audit View in the Drools Eclipse plugin, where the events are visualized as a tree. Events that occur between the before and after event are shown as children of that event. The following screenshot shows a simple example, where a process is started, resulting in the activation of the Start node, an Action node and an End node, after which the process was completed.

A common requirement when working with processes is ability to assign a given process instance some sort of business identifier that can be later on referenced without knowing the actual (generated) id of the process instance. To provide such capabilities, jBPM allows to use CorrelationKey that is composed of CorrelationProperties. CorrelationKey can have either single property describing it (which is in most cases) but it can be represented as multi valued properties set.
Correlation capabilities are provided as part of interface
CorrelationAwareProcessRuntimethat exposes following methods:
/**
* Start a new process instance. The process (definition) that should
* be used is referenced by the given process id. Parameters can be passed
* to the process instance (as name-value pairs), and these will be set
* as variables of the process instance.
*
* @param processId the id of the process that should be started
* @param correlationKey custom correlation key that can be used to identify process instance
* @param parameters the process variables that should be set when starting the process instance
* @return the ProcessInstance that represents the instance of the process that was started
*/
ProcessInstance startProcess(String processId, CorrelationKey correlationKey, Map<String, Object> parameters);
/**
* Creates a new process instance (but does not yet start it). The process
* (definition) that should be used is referenced by the given process id.
* Parameters can be passed to the process instance (as name-value pairs),
* and these will be set as variables of the process instance. You should only
* use this method if you need a reference to the process instance before actually
* starting it. Otherwise, use startProcess.
*
* @param processId the id of the process that should be started
* @param correlationKey custom correlation key that can be used to identify process instance
* @param parameters the process variables that should be set when creating the process instance
* @return the ProcessInstance that represents the instance of the process that was created (but not yet started)
*/
ProcessInstance createProcessInstance(String processId, CorrelationKey correlationKey, Map<String, Object> parameters);
/**
* Returns the process instance with the given correlationKey. Note that only active process instances
* will be returned. If a process instance has been completed already, this method will return
* null.
*
* @param correlationKey the custom correlation key assigned when process instance was created
* @return the process instance with the given id or null if it cannot be found
*/
ProcessInstance getProcessInstance(CorrelationKey correlationKey);
Correlation is usually used with long running processes and thus require persistence to be enabled to be able to permanently store correlation information.
In the following text, we will refer to two types of "multi-threading": logical and technical. Technical multi-threading is what happens when multiple threads or processes are started on a computer, for example by a Java or C program. Logical multi-threading is what we see in a BPM process after the process reaches a parallel gateway, for example. From a functional standpoint, the original process will then split into two processes that are executed in a parallel fashion.
Of course, the jBPM engine supports logical multi-threading: for example, processes that include a parallel gateway. We've chosen to implement logical multi-threading using one thread: a jBPM process that includes logical multi-threading will only be executed in one technical thread. The main reason for doing this is that multiple (technical) threads need to be be able to communicate state information with each other if they are working on the same process. This requirement brings with it a number of complications. While it might seem that multi-threading would bring performance benefits with it, the extra logic needed to make sure the different threads work together well means that this is not guaranteed. There is also the extra overhead incurred because we need to avoid race conditions and deadlocks.
In general, the jBPM engine executes actions in serial. For example,
when the engine encounters a script task in a process, it will synchronously
execute that script and wait for it to complete before continuing execution.
Similarly, if a process encounters a parallel gateway, it will sequentially
trigger each of the outgoing branches, one after the other. This is possible
since execution is almost always instantaneous, meaning that it is extremely
fast and produces almost no overhead. As a result, the user will usually
not even notice this. Similarly, action scripts in a process are also synchronously
executed, and the engine will wait for them to finish before continuing the
process. For example, doing a Thread.sleep(...) as part of
a script will not make the engine continue execution elsewhere but will
block the engine thread during that period.
The same principle applies to service tasks. When a service task is
reached in a process, the engine will also invoke the handler of this service
synchronously. The engine will wait for the completeWorkItem(...)
method to return before continuing execution. It is important that your
service handler executes your service asynchronously if its execution is
not instantaneous.
An example of this would be a service task that invokes an external service. Since the delay in invoking this service remotely and waiting for the results might be too long, it might be a good idea to invoke this service asynchronously. This means that the handler will only invoke the service and will notify the engine later when the results are available. In the mean time, the process engine then continues execution of the process.
Human tasks are a typical example of a service that needs to be invoked asynchronously, as we don't want the engine to wait until a human actor has responded to the request. The human task handler will only create a new task (on the task list of the assigned actor) when the human task node is triggered. The engine will then be able to continue execution on the rest of the process (if necessary) and the handler will notify the engine asynchronously when the user has completed the task.
RuntimeManager has been introduced to simplify and empower usage of knowledge API especially in context of processes. It provides configurable strategies that control actual runtime execution (how KieSessions are provided) and by default provides following:
- Singleton - runtime manager maintains single KieSession regardless of number of processes available
- Per Request - runtime manager delivers new KieSession for every request
- Per Process Instance - runtime manager maintains mapping between process instance and KieSession and always provides same KieSession whenever working with given process instance
Runtime Manager is primary responsible for managing and delivering instances of RuntimeEngine to the caller. In turn, RuntimeEngine encapsulates two the most important elements of jBPM engine:
KieSession
TaskService
Both of these components are already configured to work with each other smoothly without additional configuration from end user. No more need to register human task handler or keeping track if it's connected to the service or not.
public interface RuntimeManager {
/**
* Returns <code>RuntimeEngine</code> instance that is fully initialized:
* <ul>
* <li>KiseSession is created or loaded depending on the strategy</li>
* <li>TaskService is initialized and attached to ksession (via listener)</li>
* <li>WorkItemHandlers are initialized and registered on ksession</li>
* <li>EventListeners (process, agenda, working memory) are initialized and added to ksession</li>
* </ul>
* @param context the concrete implementation of the context that is supported by given <code>RuntimeManager</code>
* @return instance of the <code>RuntimeEngine</code>
*/
RuntimeEngine getRuntimeEngine(Context<?> context);
/**
* Unique identifier of the <code>RuntimeManager</code>
* @return
*/
String getIdentifier();
/**
* Disposes <code>RuntimeEngine</code> and notifies all listeners about that fact.
* This method should always be used to dispose <code>RuntimeEngine</code> that is not needed
* anymore. <br/>
* ksession.dispose() shall never be used with RuntimeManager as it will break the internal
* mechanisms of the manager responsible for clear and efficient disposal.<br/>
* Dispose is not needed if <code>RuntimeEngine</code> was obtained within active JTA transaction,
* this means that when getRuntimeEngine method was invoked during active JTA transaction then dispose of
* the runtime engine will happen automatically on transaction completion.
* @param runtime
*/
void disposeRuntimeEngine(RuntimeEngine runtime);
/**
* Closes <code>RuntimeManager</code> and releases its resources. Shall always be called when
* runtime manager is not needed any more. Otherwise it will still be active and operational.
*/
void close();
}RuntimeEngine interface provides the most important methods to get access to engine components:
public interface RuntimeEngine {
/**
* Returns <code>KieSession</code> configured for this <code>RuntimeEngine</code>
* @return
*/
KieSession getKieSession();
/**
* Returns <code>TaskService</code> configured for this <code>RuntimeEngine</code>
* @return
*/
TaskService getTaskService();
}RuntimeManager will ensure that regardless of the strategy it will provide same capabilities when it comes to initialization and configuration of the RuntimeEngine. That means
KieSession will be loaded with same factories (either in memory or JPA based)
WorkItemHandlers will be registered on every KieSession (either loaded from db or newly created)
Event listeners (Process, Agenda, WorkingMemory) will be registered on every KieSession (either loaded from db or newly created)
TaskService will be configured with:
JTA transaction manager
same entity manager factory as for the KieSession
UserGroupCallback from environment
On the other hand, RuntimeManager maintains the engine disposal as well by providing dedicated methods to dispose RuntimeEngine when it's no more needed to release any resources it might have acquired.
Note
RuntimeManager's identifier is used as "deploymentId" during runtime execution. For example, the identifier is persisted as "deploymentId" of a Task when the Task is persisted. Task's deploymentId is used to associate the RuntimeManager when the Task is completed and its process instance is resumed. The deploymentId is also persisted as "externalId" in history log tables. If you don't specify an identifier on RuntimeManager creation, a default value is applied (e.g. "default-per-pinstance" for PerProcessInstanceRuntimeManager). That means your application uses the same deployment in its lifecycle. If you maintain multiple RuntimeManagers in your application, you need to specify their identifiers. For example, jbpm-services (DeploymentService) maintains multiple RuntimeManagers with identifiers of kjar's GAV. kie-workbench web application too because it depends on jbpm-services.
Singleton strategy - instructs RuntimeManager to maintain single instance of RuntimeEngine (and in turn single instance of KieSession and TaskService). Access to the RuntimeEngine is synchronized and by that thread safe although it comes with a performance penalty due to synchronization. This strategy is similar to what was available by default in jBPM version 5.x and it's considered easiest strategy and recommended to start with.
It has following characteristics that are important to evaluate while considering it for given scenario:
small memory footprint - single instance of runtime engine and task service
simple and compact in design and usage
good fit for low to medium load on process engine due to synchronized access
due to single KieSession instance all state objects (such as facts) are directly visible to all process instances and vice versa
not contextual - meaning when retrieving instances of RuntimeEngine from singleton RuntimeManager Context instance is not important and usually EmptyContext.get() is used although null argument is acceptable as well
keeps track of id of KieSession used between RuntimeManager restarts to ensure it will use same session - this id is stored as serialized file on disc in temp location that depends on the environment can be one of following:
value given by jbpm.data.dir system property
value given by jboss.server.data.dir system property
value given by java.io.tmpdir system property
Per request strategy - instructs RuntimeManager to provide new instance of RuntimeEngine for every request. As request RuntimeManager will consider one or more invocations within single transaction. It must return same instance of RuntimeEngine within single transaction to ensure correctness of state as otherwise operation done in one call would not be visible in the other. This is sort of "stateless" strategy that provides only request scope state and once request is completed RuntimeEngine will be permanently destroyed - KieSession information will be removed from the database in case persistence was used.
It has following characteristics:
completely isolated process engine and task service operations for every request
completely stateless, storing facts makes sense only for the duration of the request
good fit for high load, stateless processes (no facts or timers involved that shall be preserved between requests)
KieSession is only available during life time of request and at the end is destroyed
not contextual - meaning when retrieving instances of RuntimeEngine from per request RuntimeManager Context instance is not important and usually EmptyContext.get() is used although null argument is acceptable as well
Per process instance strategy - instructs RuntimeManager to maintain a strict relationship between KieSession and ProcessInstance. That means that KieSession will be available as long as the ProcessInstance that it belongs to is active. This strategy provides the most flexible approach to use advanced capabilities of the engine like rule evaluation in isolation (for given process instance only), maximum performance and reduction of potential bottlenecks intriduced by synchronization; and at the same time reduces number of KieSessions to the actual number of process instances rather than number of requests (in contrast to per request strategy).
It has following characteristics:
most advanced strategy to provide isolation to given process instance only
maintains strict relationship between KieSession and ProcessInstance to ensure it will always deliver same KieSession for given ProcessInstance
merges life cycle of KieSession with ProcessInstance making both to be disposed on process instance completion (complete or abort)
allows to maintain data (such as facts, timers) in scope of process instance - only process instance will have access to that data
introduces bit of overhead due to need to look up and load KieSession for process instance
validates usage of KieSession so it cannot be (ab)used for other process instances, in such a case exception is thrown
is contextual - accepts following context instances:
EmptyContext or null - when starting process instance as there is no process instance id available yet
ProcessInstanceIdContext - used after process instance was created
CorrelationKeyContext - used as an alternative to ProcessInstanceIdContext to use custom (business) key instead of process instance id
Regular usage scenario for RuntimeManager is:
At application startup
build RuntimeManager and keep it for entire life time of the application, it's thread safe and can be (or even should be) accessed concurrently
At request
get RuntimeEngine from RuntimeManager using proper context instance dedicated to strategy of RuntimeManager
get KieSession and/or TaskService from RuntimeEngine
perform operations on KieSession and/or TaskService such as startProcess, completeTask, etc
once done with processing dispose RuntimeEngine using RuntimeManager.disposeRuntimeEngine method
At application shutdown
close RuntimeManager
Note
When RuntimeEngine is obtained from RuntimeManager within an active JTA transaction, then there is no need to dispose RuntimeEngine at the end, as RuntimeManager will automatically dispose the RuntimeEngine on transaction completion (regardless of the completion status commit or rollback).
Here is how you can build RuntimeManager and get RuntimeEngine (that encapsulates KieSession and TaskService) from it:
// first configure environment that will be used by RuntimeManager
RuntimeEnvironment environment = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultInMemoryBuilder()
.addAsset(ResourceFactory.newClassPathResource("BPMN2-ScriptTask.bpmn2"), ResourceType.BPMN2)
.get();
// next create RuntimeManager - in this case singleton strategy is chosen
RuntimeManager manager = RuntimeManagerFactory.Factory.get().newSingletonRuntimeManager(environment);
// then get RuntimeEngine out of manager - using empty context as singleton does not keep track
// of runtime engine as there is only one
RuntimeEngine runtime = manager.getRuntimeEngine(EmptyContext.get());
// get KieSession from runtime runtimeEngine - already initialized with all handlers, listeners, etc that were configured
// on the environment
KieSession ksession = runtimeEngine.getKieSession();
// add invocations to the process engine here,
// e.g. ksession.startProcess(processId);
// and last dispose the runtime engine
manager.disposeRuntimeEngine(runtimeEngine);
This example provides simplest (minimal) way of using RuntimeManager and RuntimeEngine although it provides few quite valuable information:
KieSession will be in memory only - by using newDefaultInMemoryBuilder
there will be single process available for execution - by adding it as an asset
TaskService will be configured and attached to KieSession via LocalHTWorkItemHandler to support user task capabilities within processes
The complexity of knowing when to create, dispose, register handlers, etc is taken away from the end user and moved to the runtime manager that knows when/how to perform such operations but still allows to have a fine grained control over this process by providing comprehensive configuration of the RuntimeEnvironment.
public interface RuntimeEnvironment {
/**
* Returns <code>KieBase</code> that shall be used by the manager
* @return
*/
KieBase getKieBase();
/**
* KieSession environment that shall be used to create instances of <code>KieSession</code>
* @return
*/
Environment getEnvironment();
/**
* KieSession configuration that shall be used to create instances of <code>KieSession</code>
* @return
*/
KieSessionConfiguration getConfiguration();
/**
* Indicates if persistence shall be used for the KieSession instances
* @return
*/
boolean usePersistence();
/**
* Delivers concrete implementation of <code>RegisterableItemsFactory</code> to obtain handlers and listeners
* that shall be registered on instances of <code>KieSession</code>
* @return
*/
RegisterableItemsFactory getRegisterableItemsFactory();
/**
* Delivers concrete implementation of <code>UserGroupCallback</code> that shall be registered on instances
* of <code>TaskService</code> for managing users and groups.
* @return
*/
UserGroupCallback getUserGroupCallback();
/**
* Delivers custom class loader that shall be used by the process engine and task service instances
* @return
*/
ClassLoader getClassLoader();
/**
* Closes the environment allowing to close all depending components such as ksession factories, etc
*/
void close();
While RuntimeEnvironment interface provides mostly access to data kept as part of the environment and will be used by the RuntimeManager, users should take advantage of builder style class that provides fluent API to configure RuntimeEnvironment with predefined settings.
public interface RuntimeEnvironmentBuilder {
public RuntimeEnvironmentBuilder persistence(boolean persistenceEnabled);
public RuntimeEnvironmentBuilder entityManagerFactory(Object emf);
public RuntimeEnvironmentBuilder addAsset(Resource asset, ResourceType type);
public RuntimeEnvironmentBuilder addEnvironmentEntry(String name, Object value);
public RuntimeEnvironmentBuilder addConfiguration(String name, String value);
public RuntimeEnvironmentBuilder knowledgeBase(KieBase kbase);
public RuntimeEnvironmentBuilder userGroupCallback(UserGroupCallback callback);
public RuntimeEnvironmentBuilder registerableItemsFactory(RegisterableItemsFactory factory);
public RuntimeEnvironment get();
public RuntimeEnvironmentBuilder classLoader(ClassLoader cl);
public RuntimeEnvironmentBuilder schedulerService(Object globalScheduler);
Instances of the RuntimeEnvironmentBuilder can be obtained via RuntimeEnvironmentBuilderFactory that provides preconfigured sets of builder to simplify and help users to build the environment for the RuntimeManager.
public interface RuntimeEnvironmentBuilderFactory {
/**
* Provides completely empty <code>RuntimeEnvironmentBuilder</code> instance that allows to manually
* set all required components instead of relying on any defaults.
* @return new instance of <code>RuntimeEnvironmentBuilder</code>
*/
public RuntimeEnvironmentBuilder newEmptyBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* but it does not have persistence for process engine configured so it will only store process instances in memory
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultInMemoryBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param groupId group id of kjar
* @param artifactId artifact id of kjar
* @param version version number of kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(String groupId, String artifactId, String version);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param groupId group id of kjar
* @param artifactId artifact id of kjar
* @param version version number of kjar
* @param kbaseName name of the kbase defined in kmodule.xml stored in kjar
* @param ksessionName name of the ksession define in kmodule.xml stored in kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(String groupId, String artifactId, String version, String kbaseName, String ksessionName);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param releaseId <code>ReleaseId</code> that described the kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(ReleaseId releaseId);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param releaseId <code>ReleaseId</code> that described the kjar
* @param kbaseName name of the kbase defined in kmodule.xml stored in kjar
* @param ksessionName name of the ksession define in kmodule.xml stored in kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(ReleaseId releaseId, String kbaseName, String ksessionName);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* It relies on KieClasspathContainer that requires to have kmodule.xml present in META-INF folder which
* defines the kjar itself.
* Expects to use default kbase and ksession from kmodule.
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newClasspathKmoduleDefaultBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* It relies on KieClasspathContainer that requires to have kmodule.xml present in META-INF folder which
* defines the kjar itself.
* @param kbaseName name of the kbase defined in kmodule.xml
* @param ksessionName name of the ksession define in kmodule.xml
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newClasspathKmoduleDefaultBuilder(String kbaseName, String ksessionName);Besides KieSession Runtime Manager provides access to TaskService too as integrated component of a RuntimeEngine that will always be configured and ready for communication between process engine and task service.
Since the default builder was used, it will already come with predefined set of elements that consists of:
Persistence unit name will be set to org.jbpm.persistence.jpa (for both process engine and task service)
Human Task handler will be automatically registered on KieSession
JPA based history log event listener will be automatically registered on KieSession
Event listener to trigger rule task evaluation (fireAllRules) will be automatically registered on KieSession
To extend it with your own handlers or listeners a dedicated mechanism is provided that comes as implementation of RegisterableItemsFactory
/**
* Returns new instances of <code>WorkItemHandler</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case handler need to make use of it internally
* @return map of handlers to be registered - in case of no handlers empty map shall be returned.
*/
Map<String, WorkItemHandler> getWorkItemHandlers(RuntimeEngine runtime);
/**
* Returns new instances of <code>ProcessEventListener</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case listeners need to make use of it internally
* @return list of listeners to be registered - in case of no listeners empty list shall be returned.
*/
List<ProcessEventListener> getProcessEventListeners(RuntimeEngine runtime);
/**
* Returns new instances of <code>AgendaEventListener</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case listeners need to make use of it internally
* @return list of listeners to be registered - in case of no listeners empty list shall be returned.
*/
List<AgendaEventListener> getAgendaEventListeners(RuntimeEngine runtime);
/**
* Returns new instances of <code>WorkingMemoryEventListener</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case listeners need to make use of it internally
* @return list of listeners to be registered - in case of no listeners empty list shall be returned.
*/
List<WorkingMemoryEventListener> getWorkingMemoryEventListeners(RuntimeEngine runtime);A best practice is to just extend those that come out of the box and just add your own. Extensions are not always needed as the default implementations of RegisterableItemsFactory provides possibility to define custom handlers and listeners. Following is a list of available implementations that might be useful (they are ordered in the hierarchy of inheritance):
org.jbpm.runtime.manager.impl.SimpleRegisterableItemsFactory - simplest possible implementations that comes empty and is based on reflection to produce instances of handlers and listeners based on given class names
org.jbpm.runtime.manager.impl.DefaultRegisterableItemsFactory - extension of the Simple implementation that introduces defaults described above and still provides same capabilities as Simple implementation
org.jbpm.runtime.manager.impl.KModuleRegisterableItemsFactory - extension of default implementation that provides specific capabilities for kmodule and still provides same capabilities as Simple implementation
org.jbpm.runtime.manager.impl.cdi.InjectableRegisterableItemsFactory - extension of default implementation that is tailored for CDI environments and provides CDI style approach to finding handlers and listeners via producers
Alternatively, simple (stateless or requiring only KieSession) work item handlers might be registered in the well known way - defined as part of CustomWorkItem.conf file that shall be placed on class path. To use this approach do following:
create file "drools.session.conf" inside META-INF of the root of the class path, for web applications it will be WEB-INF/classes/META-INF
add following line to drools.session.conf file "drools.workItemHandlers = CustomWorkItemHandlers.conf"
create file "CustomWorkItemHandlers.conf" inside META-INF of the root of the class path, for web applications it will be WEB-INF/classes/META-INF
define custom work item handlers in MVEL style inside CustomWorkItemHandlers.conf
[ "Log": new org.jbpm.process.instance.impl.demo.SystemOutWorkItemHandler(), "WebService": new org.jbpm.process.workitem.webservice.WebServiceWorkItemHandler(ksession), "Rest": new org.jbpm.process.workitem.rest.RESTWorkItemHandler(), "Service Task" : new org.jbpm.process.workitem.bpmn2.ServiceTaskHandler(ksession) ]
And that's it, now all these work item handlers will be registered for any KieSession created by that application, regardless if it uses RuntimeManager or not.
When using RuntimeManager in CDI environment there are dedicated interfaces that can be used to provide custom WorkItemHandlers and EventListeners to the RuntimeEngine.
public interface WorkItemHandlerProducer {
/**
* Returns map of (key = work item name, value work item handler instance) of work items
* to be registered on KieSession
* <br/>
* Parameters that might be given are as follows:
* <ul>
* <li>ksession</li>
* <li>taskService</li>
* <li>runtimeManager</li>
* </ul>
*
* @param identifier - identifier of the owner - usually RuntimeManager that allows the producer to filter out
* and provide valid instances for given owner
* @param params - owner might provide some parameters, usually KieSession, TaskService, RuntimeManager instances
* @return map of work item handler instances (recommendation is to always return new instances when this method is invoked)
*/
Map<String, WorkItemHandler> getWorkItemHandlers(String identifier, Map<String, Object> params);
}Event listener producer shall be annotated with proper qualifier to indicate what type of listeners they provide, so pick one of following to indicate they type:
@Process - for ProcessEventListener
@Agenda - for AgendaEventListener
@WorkingMemory - for WorkingMemoryEventListener
public interface EventListenerProducer<T> {
/**
* Returns list of instances for given (T) type of listeners
* <br/>
* Parameters that might be given are as follows:
* <ul>
* <li>ksession</li>
* <li>taskService</li>
* <li>runtimeManager</li>
* </ul>
* @param identifier - identifier of the owner - usually RuntimeManager that allows the producer to filter out
* and provide valid instances for given owner
* @param params - owner might provide some parameters, usually KieSession, TaskService, RuntimeManager instances
* @return list of listener instances (recommendation is to always return new instances when this method is invoked)
*/
List<T> getEventListeners(String identifier, Map<String, Object> params);
}Implementations of these interfaces shall be packaged as bean archive (includes beans.xml inside META-INF) and placed on application classpath (e.g. WEB-INF/lib for web application). THat is enough for CDI based RuntimeManager to discover them and register on every KieSession that is created or loaded from data store.
Some parameters are provided to the producers to allow handlers/listeners to be more stateful and be able to do more advanced things with the engine - like signal of the engine or process instance in case of an error. Thus all components are provided:
KieSession
TaskService
RuntimeManager
Note
Whenever there is a need to interact with the process engine/task service from within handler or listener, recommended approach is to use RuntimeManager and retrieve RuntimeEngine (and then KieSession and/or TaskService) from it as that will ensure proper state managed according to strategy
In addition, some filtering can be applied based on identifier (that is given as argument to the methods) to decide if given RuntimeManager shall receive handlers/listeners or not.
On top of RuntimeManager API a set of high level services has been provided from jBPM version 6.2. These services are meant to be the easiest way to embed (j)BPM capabilities into custom application. A complete set of modules are delivered as part of these services. They are partitioned into several modules to ease thier adoptions in various environments.
jbpm-services-api
contains only api classes and interfaces
jbpm-kie-services
rewritten code implementation of services api - pure java, no framework dependencies
jbpm-services-cdi
CDI wrapper on top of core services implementation
jbpm-services-ejb-api
extension to services api for ejb needs
jbpm-services-ejb-impl
EJB wrappers on top of core services implementation
jbpm-services-ejb-timer
scheduler service based on EJB TimerService to support time based operations e.g. timer events, deadlines, etc
jbpm-services-ejb-client
EJB remote client implementation - currently only for JBoss
Service modules are grouped with its framework dependencies, so developers are free to choose which one is suitable for them and use only that.
As the name suggest, its primary responsibility is to deploy (and undeploy) units. Deployment unit is kjar that brings in business assets (like processes, rules, forms, data model) for execution. Deployment services allow to query it to get hold of available deployment units and even their RuntimeManager instances.
Note
there are some restrictions on EJB remote client to do not expose RuntimeManager as it won't make any sense on client side (after it was serialized).
So typical use case for this service is to provide dynamic behavior into your system so multiple kjars can be active at the same time and be executed simultaneously.
// create deployment unit by giving GAV
DeploymentUnit deploymentUnit = new KModuleDeploymentUnit(GROUP_ID, ARTIFACT_ID, VERSION);
// deploy
deploymentService.deploy(deploymentUnit);
// retrieve deployed unit
DeployedUnit deployed = deploymentService.getDeployedUnit(deploymentUnit.getIdentifier());
// get runtime manager
RuntimeManager manager = deployed.getRuntimeManager();
Complete DeploymentService interface is as follows:
public interface DeploymentService {
void deploy(DeploymentUnit unit);
void undeploy(DeploymentUnit unit);
RuntimeManager getRuntimeManager(String deploymentUnitId);
DeployedUnit getDeployedUnit(String deploymentUnitId);
Collection<DeployedUnit> getDeployedUnits();
void activate(String deploymentId);
void deactivate(String deploymentId);
boolean isDeployed(String deploymentUnitId);
}Upon deployment, every process definition is scanned using definition service that parses the process and extracts valuable information out of it. These information can provide valuable input to the system to inform users about what is expected. Definition service provides information about:
process definition - id, name, description
process variables - name and type
reusable subprocesses used in the process (if any)
service tasks (domain specific activities)
user tasks including assignment information
task data input and output information
So definition service can be seen as sort of supporting service that provides quite a few information about process definition that are extracted directly from BPMN2.
String processId = "org.jbpm.writedocument";
Collection<UserTaskDefinition> processTasks =
bpmn2Service.getTasksDefinitions(deploymentUnit.getIdentifier(), processId);
Map<String, String> processData =
bpmn2Service.getProcessVariables(deploymentUnit.getIdentifier(), processId);
Map<String, String> taskInputMappings =
bpmn2Service.getTaskInputMappings(deploymentUnit.getIdentifier(), processId, "Write a Document" );
While it usually is used with combination of other services (like deployment service) it can be used standalone as well to get details about process definition that do not come from kjar. This can be achieved by using buildProcessDefinition method of definition service.
public interface DefinitionService {
ProcessDefinition buildProcessDefinition(String deploymentId, String bpmn2Content,
ClassLoader classLoader, boolean cache) throws IllegalArgumentException;
ProcessDefinition getProcessDefinition(String deploymentId, String processId);
Collection<String> getReusableSubProcesses(String deploymentId, String processId);
Map<String, String> getProcessVariables(String deploymentId, String processId);
Map<String, String> getServiceTasks(String deploymentId, String processId);
Map<String, Collection<String>> getAssociatedEntities(String deploymentId, String processId);
Collection<UserTaskDefinition> getTasksDefinitions(String deploymentId, String processId);
Map<String, String> getTaskInputMappings(String deploymentId, String processId, String taskName);
Map<String, String> getTaskOutputMappings(String deploymentId, String processId, String taskName);
}Process service is the one that usually is of the most interest. Once the deployment and definition service was already used to feed the system with something that can be executed. Process service provides access to execution environment that allows:
start new process instance
work with existing one - signal, get details of it, get variables, etc
work with work items
At the same time process service is a command executor so it allows to execute commands (essentially on ksession) to extend its capabilities.
Important to note is that process service is focused on runtime operations so use it whenever there is a need to alter (signal, change variables, etc) process instance and not for read operations like show available process instances by looping though given list and invoking getProcessInstance method. For that there is dedicated runtime data service that is described below.
An example on how to deploy and run process can be done as follows:
KModuleDeploymentUnit deploymentUnit = new KModuleDeploymentUnit(GROUP_ID, ARTIFACT_ID, VERSION);
deploymentService.deploy(deploymentUnit);
long processInstanceId = processService.startProcess(deploymentUnit.getIdentifier(), "customtask");
ProcessInstance pi = processService.getProcessInstance(processInstanceId);
As you can see start process expects deploymentId as first argument. This is extremely powerful to enable service to easily work with various deployments, even with same processes but coming from different versions - kjar versions.
public interface ProcessService {
Long startProcess(String deploymentId, String processId);
Long startProcess(String deploymentId, String processId, Map<String, Object> params);
void abortProcessInstance(Long processInstanceId);
void abortProcessInstances(List<Long> processInstanceIds);
void signalProcessInstance(Long processInstanceId, String signalName, Object event);
void signalProcessInstances(List<Long> processInstanceIds, String signalName, Object event);
ProcessInstance getProcessInstance(Long processInstanceId);
void setProcessVariable(Long processInstanceId, String variableId, Object value);
void setProcessVariables(Long processInstanceId, Map<String, Object> variables);
Object getProcessInstanceVariable(Long processInstanceId, String variableName);
Map<String, Object> getProcessInstanceVariables(Long processInstanceId);
Collection<String> getAvailableSignals(Long processInstanceId);
void completeWorkItem(Long id, Map<String, Object> results);
void abortWorkItem(Long id);
WorkItem getWorkItem(Long id);
List<WorkItem> getWorkItemByProcessInstance(Long processInstanceId);
public <T> T execute(String deploymentId, Command<T> command);
public <T> T execute(String deploymentId, Context<?> context, Command<T> command);
}Runtime data service as name suggests, deals with all that refers to runtime information:
started process instances
executed node instances
executed node instances
and more
Use this service as main source of information whenever building list based UI - to show process definitions, process instances, tasks for given user, etc. This service was designed to be as efficient as possible and still provide all required information.
Some examples:
get all process definitions
Collection definitions = runtimeDataService.getProcesses(new QueryContext());get active process instances
Collection<processinstancedesc> instances = runtimeDataService.getProcessInstances(new QueryContext());get active nodes for given process instance
Collection<nodeinstancedesc> instances = runtimeDataService.getProcessInstanceHistoryActive(processInstanceId, new QueryContext());get tasks assigned to john
List<tasksummary> taskSummaries = runtimeDataService.getTasksAssignedAsPotentialOwner("john", new QueryFilter(0, 10));
There are two important arguments that the runtime data service operations supports:
QueryContext
QueryFilter - extension of QueryContext
These provide capabilities for efficient management result set like pagination, sorting and ordering (QueryContext). Moreover additional filtering can be applied to task queries to provide more advanced capabilities when searching for user tasks.
public interface RuntimeDataService {
// Process instance information
Collection<ProcessInstanceDesc> getProcessInstances(QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstances(List<Integer> states, String initiator, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessId(List<Integer> states, String processId, String initiator, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessName(List<Integer> states, String processName, String initiator, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByDeploymentId(String deploymentId, List<Integer> states, QueryContext queryContext);
ProcessInstanceDesc getProcessInstanceById(long processInstanceId);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessDefinition(String processDefId, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessDefinition(String processDefId, List<Integer> states, QueryContext queryContext);
// Node and Variable instance information
NodeInstanceDesc getNodeInstanceForWorkItem(Long workItemId);
Collection<NodeInstanceDesc> getProcessInstanceHistoryActive(long processInstanceId, QueryContext queryContext);
Collection<NodeInstanceDesc> getProcessInstanceHistoryCompleted(long processInstanceId, QueryContext queryContext);
Collection<NodeInstanceDesc> getProcessInstanceFullHistory(long processInstanceId, QueryContext queryContext);
Collection<NodeInstanceDesc> getProcessInstanceFullHistoryByType(long processInstanceId, EntryType type, QueryContext queryContext);
Collection<VariableDesc> getVariablesCurrentState(long processInstanceId);
Collection<VariableDesc> getVariableHistory(long processInstanceId, String variableId, QueryContext queryContext);
// Process information
Collection<ProcessDefinition> getProcessesByDeploymentId(String deploymentId, QueryContext queryContext);
Collection<ProcessDefinition> getProcessesByFilter(String filter, QueryContext queryContext);
Collection<ProcessDefinition> getProcesses(QueryContext queryContext);
Collection<String> getProcessIds(String deploymentId, QueryContext queryContext);
ProcessDefinition getProcessById(String processId);
ProcessDefinition getProcessesByDeploymentIdProcessId(String deploymentId, String processId);
// user task query operations
UserTaskInstanceDesc getTaskByWorkItemId(Long workItemId);
UserTaskInstanceDesc getTaskById(Long taskId);
List<TaskSummary> getTasksAssignedAsBusinessAdministrator(String userId, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsBusinessAdministratorByStatus(String userId, List<Status> statuses, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwner(String userId, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwner(String userId, List<String> groupIds, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwnerByStatus(String userId, List<Status> status, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwner(String userId, List<String> groupIds, List<Status> status, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwnerByExpirationDateOptional(String userId, List<Status> status, Date from, QueryFilter filter);
List<TaskSummary> getTasksOwnedByExpirationDateOptional(String userId, List<Status> strStatuses, Date from, QueryFilter filter);
List<TaskSummary> getTasksOwned(String userId, QueryFilter filter);
List<TaskSummary> getTasksOwnedByStatus(String userId, List<Status> status, QueryFilter filter);
List<Long> getTasksByProcessInstanceId(Long processInstanceId);
List<TaskSummary> getTasksByStatusByProcessInstanceId(Long processInstanceId, List<Status> status, QueryFilter filter);
List<AuditTask> getAllAuditTask(String userId, QueryFilter filter);
}User task service covers complete life cycle of individual task so it can be managed from start to end. It explicitly eliminates queries from it to provide scoped execution and moves all query operations into runtime data service. Besides lifecycle operations user task service allows:
modification of selected properties
access to task variables
access to task attachments
access to task comments
On top of that user task service is a command executor as well that allows to execute custom task commands.
Complete example with start process and complete user task done by services:
long processInstanceId =
processService.startProcess(deployUnit.getIdentifier(), "org.jbpm.writedocument");
List<Long> taskIds =
runtimeDataService.getTasksByProcessInstanceId(processInstanceId);
Long taskId = taskIds.get(0);
userTaskService.start(taskId, "john");
UserTaskInstanceDesc task = runtimeDataService.getTaskById(taskId);
Map<String, Object> results = new HashMap<String, Object>();
results.put("Result", "some document data");
userTaskService.complete(taskId, "john", results);
Note
The most important thing when working with services is that there is no more need to create your own implementations of Process service that simply wraps runtime manager, runtime engine, ksession usage. Services make use of RuntimeManager API best practices and thus eliminate various risks when working with that API.
QueryService provides advanced search capabilities that are based on Dashbuilder DataSets. The concept behind it is that users are given control over how to retrieve data from underlying data store. This includes complex joins with external tables such as JPA entities tables, custom systems data base tables etc.
QueryService is build around two parts:
Management operations
register query definition
replace query definition
unregister (remove) query definition
get query definition
get all registered query definitions
Runtime operations
query - with two flavors
simple based on QueryParam as filter provider
advanced based on QueryParamBuilder as filter provider
DashBuilder DataSets provide support for multiple data sources (CSV, SQL, elastic search, etc) while jBPM - since its backend is RDBMS based - focuses on SQL based data sets. So jBPM QueryService is a subset of DashBuilder DataSets capabilities to allow efficient queries with simple API.
Terminology
QueryDefinition - represents definion of the data set which consists of unique name, sql expression (the query) and source - JNDI name of the data source to use when performing queries
QueryParam - basic structure that represents individual query parameter - condition - that consists of: column name, operator, expected value(s)
QueryResultMapper - responsible for mapping raw data set data (rows and columns) into object representation
QueryParamBuilder - responsible for building query filters that will be applied on the query definition for given query invocation
While QueryDefinition and QueryParam is rather straight forward, QueryParamBuilder and QueryResultMapper is bit more advanced and require slightly more attention to make use of it in right way, and by that take advantage of their capabilities.
QueryResultMapper
Mapper as the name suggest, maps data taken out from data base (from data set) into object representation. Much like ORM providers such as hibernate maps tables to entities. Obviously there might be many object types that could be used for representing data set results so it's almost impossible to provide them out of the box. Mappers are rather powerful and thus are pluggable, you can implement your own that will transform the result into whatever type you like. jBPM comes with following mappers out of the box:
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceQueryMapper
registered with name - ProcessInstances
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceWithVarsQueryMapper
registered with name - ProcessInstancesWithVariables
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceWithCustomVarsQueryMapper
registered with name - ProcessInstancesWithCustomVariables
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceQueryMapper
registered with name - UserTasks
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceWithVarsQueryMapper
registered with name - UserTasksWithVariables
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceWithCustomVarsQueryMapper
registered with name - UserTasksWithCustomVariables
org.jbpm.kie.services.impl.query.mapper.TaskSummaryQueryMapper
registered with name - TaskSummaries
org.jbpm.kie.services.impl.query.mapper.RawListQueryMapper
registered with name - RawList
Each QueryResultMapper is registered under given name to allow simple look up by name instead of referencing its class name - especially important when using EJB remote flavor of services where we want to reduce number of dependencies and thus not relying on implementation on client side. So to be able to reference QueryResultMapper by name, NamedQueryMapper should be used which is part of jbpm-services-api. That acts as delegate (lazy delegate) as it will look up the actual mapper when the query is actually performed.
queryService.query("my query def", new NamedQueryMapper<Collection<ProcessInstanceDesc>>("ProcessInstances"), new QueryContext());
QueryParamBuilder
QueryParamBuilder that provides more advanced way of building filters for our data sets. By default when using query method of QueryService that accepts zero or more QueryParam instances (as we have seen in above examples) all of these params will be joined with AND operator meaning all of them must match. But that's not always the case so that's why QueryParamBuilder has been introduced for users to build their on builders which will provide filters at the time the query is issued.
There is one QueryParamBuilder available out of the box and it is used to cover default QueryParams that are based on so called core functions. These core functions are SQL based conditions and includes following
IS_NULL
NOT_NULL
EQUALS_TO
NOT_EQUALS_TO
LIKE_TO
GREATER_THAN
GREATER_OR_EQUALS_TO
LOWER_THAN
LOWER_OR_EQUALS_TO
BETWEEN
IN
NOT_IN
QueryParamBuilder is simple interface that is invoked as long as its build method returns non null value before query is performed. So you can build up a complex filter options that could not be simply expressed by list of QueryParams. Here is basic implementation of QueryParamBuilder to give you a jump start to implement your own - note that it relies on DashBuilder Dataset API.
public class TestQueryParamBuilder implements QueryParamBuilder<ColumnFilter> {
private Map<String, Object> parameters;
private boolean built = false;
public TestQueryParamBuilder(Map<String, Object> parameters) {
this.parameters = parameters;
}
@Override
public ColumnFilter build() {
// return null if it was already invoked
if (built) {
return null;
}
String columnName = "processInstanceId";
ColumnFilter filter = FilterFactory.OR(
FilterFactory.greaterOrEqualsTo((Long)parameters.get("min")),
FilterFactory.lowerOrEqualsTo((Long)parameters.get("max")));
filter.setColumnId(columnName);
built = true;
return filter;
}
}
Once you have query param builder implemented you simply use its instance when performing query via QueryService
queryService.query("my query def", ProcessInstanceQueryMapper.get(), new QueryContext(), paramBuilder);Typical usage scenario
First thing user needs to do is to define data set - view of the data you want to work with - so called QueryDefinition in services api.
SqlQueryDefinition query = new SqlQueryDefinition("getAllProcessInstances", "java:jboss/datasources/ExampleDS");
query.setExpression("select * from processinstancelog");
This is the simplest possible query definition as it can be:
constructor takes
a unique name that identifies it on runtime
data source JNDI name used when performing queries on this definition - in other words source of data
expression - the most important part - is the sql statement that builds up the view to be filtered when performing queries
Once we have the sql query definition we can register it so it can be used later for actual queries.
queryService.registerQuery(query);
From now on, this query definition can be used to perform actual queries (or data look ups to use terminology from data sets). Following is the basic one that collects data as is, without any filtering
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext());
Above query was very simple and used defaults from QueryContext - paging and sorting. So let's take a look at one that changes the defaults of the paging and sorting
QueryContext ctx = new QueryContext(0, 100, "start_date", true);
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), ctx);
Now let's take a look at how to do data filtering
// single filter param
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext(), QueryParam.likeTo(COLUMN_PROCESSID, true, "org.jbpm%"));
// multiple filter params (AND)
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext(),
QueryParam.likeTo(COLUMN_PROCESSID, true, "org.jbpm%"),
QueryParam.in(COLUMN_STATUS, 1, 3));
With that end user is put in driver seat to define what data and how they should be fetched. Not being limited by JPA provider nor anything else. Moreover this promotes use of tailored queries for your environment as in most of the case there will be single data base used and thus specific features of that data base can be used to increase performance.
Further examples can be found here.
ProcessInstanceMigrationService provides administrative utility to move given process instance(s) from one deployment to another or one process definition to another. It’s main responsibility is to allow basic upgrade of process definition behind given process instance. That might include mapping of currently active nodes to other nodes in new definition.
Migration does not deal with process or task variables, they are not affected by migration. Essentially process instance migration means a change of underlying process definition process engine uses to move on with process instance.
Even though process instance migration is available it’s recommended to let active process instances finish and then start new instances with new version whenever possible. In case that approach can’t be used, migration of active process instance needs to be carefully planned before its execution as it might lead to unexpected issues.Most important to take into account is:
is new process definition backward compatible?
are there any data changes (variables that could affect process instance decisions after migration)?
is there need for node mapping?
Answers to these questions might save a lot of headache and production problems after migration. Best is to always stick with backward compatible processes - like extending process definition rather than removing nodes. Though that’s not always possible and in some cases there is a need to remove certain nodes from process definition. In that situation, migration needs to be instructed how to map nodes that were removed in new definition in case active process instance is at the moment in such a node.
Node mapping is given as a map of node ids (UniqueIds that are set in the definition) where key is the source node id (from process definition used by process instance) to target node id (in new process definition).
Note
Node mapping can only be used to map same type of nodes e.g. user task to user task.
Again, process or task variables are not affected by process instance migration at the moment.
ProcessInstanceMigrationService comes with several flavors of migrate operation:
public interface ProcessInstanceMigrationService {
/**
* Migrates given process instance that belongs to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns migration report regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceId id of the process instance to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @return returns complete migration report
*/
MigrationReport migrate(String sourceDeploymentId, Long processInstanceId, String targetDeploymentId, String targetProcessId);
/**
* Migrates given process instance (with node mapping) that belongs to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns migration report regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceId id of the process instance to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @param nodeMapping node mapping - source and target unique ids of nodes to be mapped - from process instance active nodes to new process nodes
* @return returns complete migration report
*/
MigrationReport migrate(String sourceDeploymentId, Long processInstanceId, String targetDeploymentId, String targetProcessId, Map<String, String> nodeMapping);
/**
* Migrates given process instances that belong to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns list of migration report - one per process instance, regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceIds list of process instance id to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @return returns complete migration report
*/
List<MigrationReport> migrate(String sourceDeploymentId, List<Long> processInstanceIds, String targetDeploymentId, String targetProcessId);
/**
* Migrates given process instances (with node mapping) that belong to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns list of migration report - one per process instance, regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceIds list of process instance id to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @param nodeMapping node mapping - source and target unique ids of nodes to be mapped - from process instance active nodes to new process nodes
* @return returns list of migration reports one per each process instance
*/
List<MigrationReport> migrate(String sourceDeploymentId, List<Long> processInstanceIds, String targetDeploymentId, String targetProcessId, Map<String, String> nodeMapping);
}
Migration can either be performed for single process instance or multiple process instances at the same time. Multiple process instances migration is a utility method on top of single instance, instead of calling it multiple times, users call it once and then service will take care of the migration of individual process instances.
Note
Multi instance migration does migrate each instance in separation (transaction) to secure that one won't affect the other and then produces dedicated migration reports for each process instance
Migration is always comcluded with migration report that is per each process instance. That migration report provides following information:
start and end date of the migration
outcome of the migration - success or failure
complete log entry - all steps performed during migration, entry can be INFO, WARN or ERROR - in case of ERROR there will be at most one as they are causing migration to be immedietely terminated.
When a new or modified task requires inputs which are not available in the migrated v2 process instance.
Modifying the tasks prior to the active task where the changes have an impact on the further processing.
Removing a human task which is currently active (can only be replaced - requires to be mapped to another human task)
Adding a new task parallel to the single active task (all branches in AND gateway are not activated - process will stuck)
Changing or removing the active recurring timer events (won’t be changed in DB)
Fixing or updating inputs and outputs in an active task (task data aren’t migrated)
Node mapping updates only the task node name and description! (other task fields won’t be mapped including the TaskName variable)
Following is an example of how to invoke the migration
protected static final String MIGRATION_ARTIFACT_ID = "test-migration";
protected static final String MIGRATION_GROUP_ID = "org.jbpm.test";
protected static final String MIGRATION_VERSION_V1 = "1.0.0";
protected static final String MIGRATION_VERSION_V2 = "2.0.0";
// first deploy both versions
deploymentUnitV1 = new KModuleDeploymentUnit(MIGRATION_GROUP_ID, MIGRATION_ARTIFACT_ID, MIGRATION_VERSION_V1);
deploymentService.deploy(deploymentUnitV1);
// ... version 2
deploymentUnitV2 = new KModuleDeploymentUnit(MIGRATION_GROUP_ID, MIGRATION_ARTIFACT_ID, MIGRATION_VERSION_V2);
deploymentService.deploy(deploymentUnitV2);
// next start process instance in version 1
long processInstanceId = processService.startProcess(deploymentUnitV1.getIdentifier(), "processID-V1");
// and once the instance is active it can be migrated
MigrationReport report = migrationService.migrate(deploymentUnitV1.getIdentifier(), processInstanceId, deploymentUnitV2.getIdentifier(), "processID-V2");
// as last step check if the migration finished successfully
report.isSuccessful()Deployment Service provides convinient way to put business assets to an execution environment but there are cases that requires some additional management to make them available in right context.
Activation and Deactivation of deployments
Imagine situation where there are number of processes already running of given deployment and then new version of these processes comes into the runtime environment. With that administrator can decide that new instances of given process definition should be using new version only while already active instances should continue with the previous version.
To help with that deployment service has been equipped with following methods:
activate
allows to activate given deployment so it can be available for interaction meaning will show its process definition and allow to start new process instances of that project's processes
deactivate
allows to deactivate deployment which will disable option to see or start new process instances of that project's processes but will allow to continue working with already active process instances, e.g. signal, work with user task etc
This feature allows smooth transition between project versions whitout need of process instance migration.
Deployment synchronization
Prior to jBPM 6.2, jbpm services did not have deployment store by default. When embedded in jbpm-console/kie-wb they utilized sistem.git VFS repository to preserve deployed units across server restarts. While that works fine, it comes with some drawbacks:
not available for custom systems that use services
requires complex setup in cluster - zookeeper and helix
With version 6.2 jbpm services come with deployment synchronizer that stores available deployments into data base, including its deployment descriptor. At the same time it constantly monitors that table to keep it in sync with other installations that might be using same data source. This is especially important when running in cluster or when jbpm console runs next to custom application and both should be able to operate on the same artifacts.
By default synchronization must be configured (when runing as core services while it is automatically enabled for ejb and cdi extensions). To configure synchronization following needs to be configured:
TransactionalCommandService commandService = new TransactionalCommandService(emf);
DeploymentStore store = new DeploymentStore();
store.setCommandService(commandService);
DeploymentSynchronizer sync = new DeploymentSynchronizer();
sync.setDeploymentService(deploymentService);
sync.setDeploymentStore(store);
DeploymentSyncInvoker invoker = new DeploymentSyncInvoker(sync, 2L, 3L, TimeUnit.SECONDS);
invoker.start();
....
invoker.stop();
With this, deployments will be synchronized every 3 seconds with initial delay of two seconds.
Invoking latest version of project's processes
In case there is a need to always work with latest version of project's process, services allow to interact with various operations using deployment id with latest keyword. Let's go over an example to better understand the feature.
Initially deployed unit is org.jbpm:HR:1.0 which has the first version of an hiring process. After several weeks, new version is developed and deployed to the execution server - org.jbpm:HR.2.0 with version 2 of the hiring process.
To allow callers of the services to interact without being worried if they work with latest version, they can use following deployment id:
org.jbpm.HR:latestthis will alwyas find out latest available version of project that is identified by:
groupId: org.jbpm
artifactId: HR
version comparizon is based on Maven version numbers and relies on Maen based algorithm to find the latest one.
Note
This is only supported when process identifier remains the same in all project versions
Here is a complete example with deployment of multiple versions and interacting always with the latest:
KModuleDeploymentUnit deploymentUnitV1 = new KModuleDeploymentUnit("org.jbpm", "HR", "1.0");
deploymentService.deploy(deploymentUnitV1);
long processInstanceId = processService.startProcess("org.jbpm:HR:LATEST", "customtask");
ProcessInstanceDesc piDesc = runtimeDataService.getProcessInstanceById(processInstanceId);
// we have started process with project's version 1
assertEquals(deploymentUnitV1.getIdentifier(), piDesc.getDeploymentId());
// next we deploy version 1
KModuleDeploymentUnit deploymentUnitV2 = new KModuleDeploymentUnit("org.jbpm", "HR", "2.0");
deploymentService.deploy(deploymentUnitV2);
processInstanceId = processService.startProcess("org.jbpm:HR:LATEST", "customtask");
piDesc = runtimeDataService.getProcessInstanceById(processInstanceId);
// this time we have started process with project's version 2
assertEquals(deploymentUnitV2.getIdentifier(), piDesc.getDeploymentId());As illustrated this provides very powerful feature when interacting with frequently chaning environment that allows to always be up to date when it comes to use of process definitions.
Note
This feature is also available in REST interface so whenever sending request with deployment id, it's enough to replace concrete version with LATEST keyword to make use of this feature.
There are several control parameters available to alter engine default behavior. This allows to fine tune the execution for the environment needs and actual requirements. All of these parameters are set as JVM system properties, usually with -D when starting program e.g. application server.
Table 5.1. Control parameters
| Name | Possible values | Default value | Description | |
|---|---|---|---|---|
| jbpm.ut.jndi.lookup | String | Alternative JNDI name to be used when there is no access to the default one (java:comp/UserTransaction) | ||
| jbpm.enable.multi.con | true|false | false | Enables multiple incoming/outgoing sequence flows support for activities | |
| jbpm.business.calendar.properties | String | /jbpm.business.calendar.properties | Allows to provide alternative classpath location of business calendar configuration file | |
| jbpm.overdue.timer.delay | Long | 2000 | Specifies delay for overdue timers to allow proper initialization, in milliseconds | |
| jbpm.process.name.comparator | String | Allows to provide alternative comparator class to empower start process by name feature, if not set NumberVersionComparator is used | ||
| jbpm.loop.level.disabled | true|false | true | Allows to enable or disable loop iteration tracking, to allow advanced loop support when using XOR gateways | |
| org.kie.mail.session | String | mail/jbpmMailSession | Allows to provide alternative JNDI name for mail session used by Task Deadlines | |
| jbpm.usergroup.callback.properties | String | /jbpm.usergroup.callback.properties | Allows to provide alternative classpath location for user group callback implementation (LDAP, DB) | |
| jbpm.user.group.mapping | String | ${jboss.server.config.dir}/roles.properties | Allows to provide alternative location of roles.properties for JBossUserGroupCallbackImpl | |
| jbpm.user.info.properties | String | /jbpm.user.info.properties | Allows to provide alternative classpath location of user info configuration (used by LDAPUserInfoImpl) | |
| org.jbpm.ht.user.separator | String | , | Allows to provide alternative separator of actors and groups for user tasks, default is comma (,) | |
| org.quartz.properties | String | Allows to provide location of the quartz config file to activate quartz based timer service | ||
| jbpm.data.dir | String | ${jboss.server.data.dir} is available otherwise ${java.io.tmpdir} | Allows to provide location where data files produced by jbpm should be stored | |
| org.kie.executor.pool.size | Integer | 1 | Allows to provide thread pool size for jbpm executor | |
| org.kie.executor.retry.count | Integer | 3 | Allows to provide number of retries attempted in case of error by jbpm executor | |
| org.kie.executor.interval | Integer | 3 | Allows to provide frequency used to check for pending jobs by jbpm executor, in seconds | |
| org.kie.executor.disabled | true|false | true | Enables or disable jbpm executor | |
| org.kie.store.services.class | String | org.drools.persistence.jpa.KnowledgeStoreServiceImpl | Fully qualified name of the class that implements KieStoreServices that will be responsible for bootstraping KieSession instances |