The following features were added to jBPM 6.5
jbpm services module has been extended with admin capability to allow basic process instance migration. Service primary targets migration of process instance:
between deployments (kjars)
between process definitions
Optionally it allows to perform node mapping of active node instances within process instance.
Kie Server client has been enhanced to support various response handlers for JMS based integration. By default it stays as in previous version (request reply interaction pattern) but allows to select another one that might fit better for some uses cases:
fire and forget - essentially means there won’t be any response
asynchronous with callback - response to the message will be delivered asynchronously to given callback
6.5 comes with enhancement for accessing task variables (both input and output) from within task event listener. Once there is a need to get hold of task variables in the listener it’s enough to call:
@Override
public void beforeTaskStartedEvent(TaskEvent event) {
Task task = event.getTask();
event.getTaskContext().loadTaskVariables(task);
Map<String, Object> inputVariables = task.getTaskInputVariables();
Map<String, Object> outputVariables = task.getTaskOutputVariables();
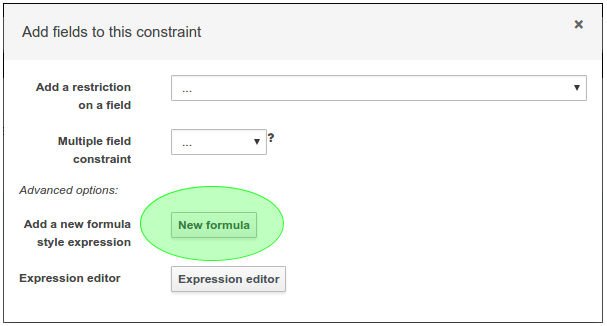
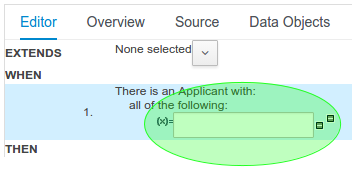
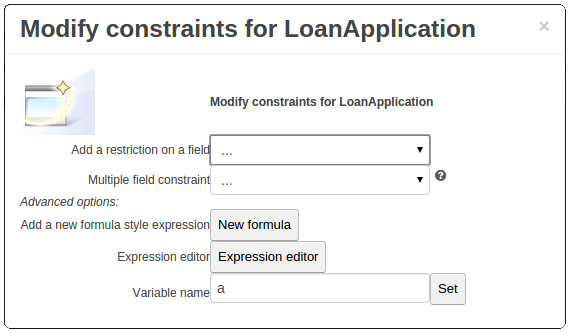
}Composite field constraints now support use of formulae.
When adding constraints to a Pattern the "Multiple Field Constraint" selection ("All of (and)" and "Any of (or)") supports use of formulae in addition to expressions.
The following features were added to jBPM 6.4
The jBPM Process Dashboard has been entirely rewritten in this version and now is based on a native workbench perspective instead of a separated web application. The main goal is to deliver a better user experience, thanks to a much more appealing as well as polished user interface.
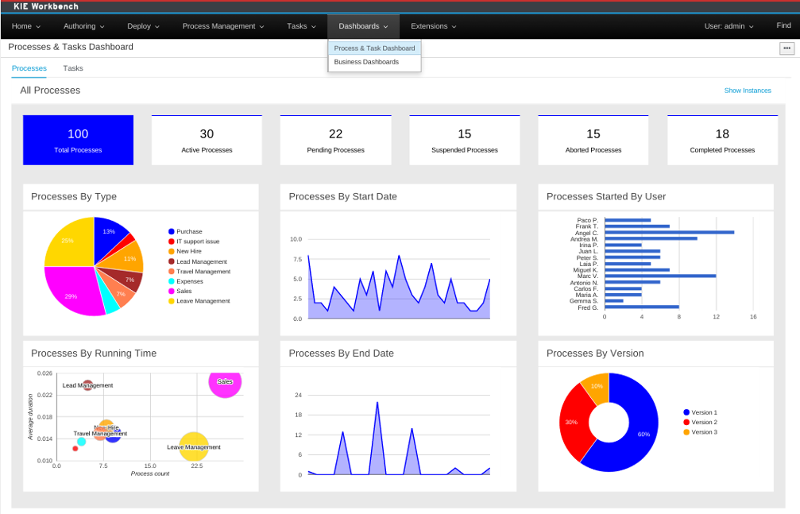
This dashboard version also provides the ability to navigate from the graphical indicators to any of the related process or task instances. Now, end users can easily find out the instances that are related to a given indicator and deep into their details as well.
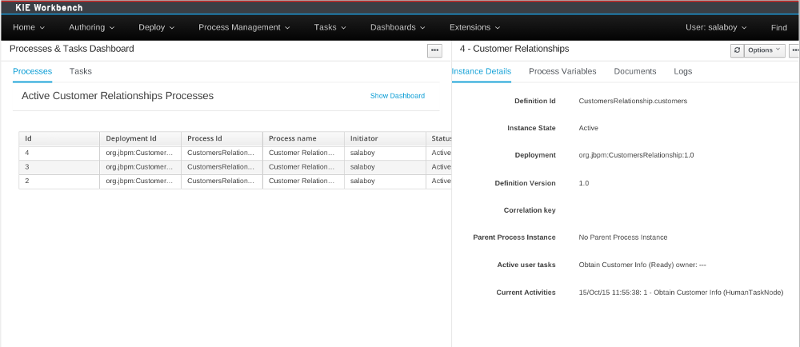
The resulting dashboard is more fluent, more interactive and with a better integration with the jBPM runtime.
By default process variables are stored in audit tables (VariableInstanceLog) that allows simplified access to variable values without need to load individual process instances. Moreover that provides option to search by process variables and process variable values e.g. to find process instances that have given value for given variable.
This was missing for task variables as task variables were not stored in any audit tables. This has been improved in version 6.4.0 and now task variables are stored in audit table (TaskVariableImpl) by default. It does follow the same mechanism as for process variables - variable.toString() is the value stored in table. With this services and query APIs have been enhanced to take advantage of this support and to search for tasks by their variables.
By default process and task variables are indexed with simplest possible mechanism - that is variable.toString() while for some object this can be sufficient, like simple types, for others it can cause significant problems when performing queries. To solve the problem process and task variables are equipped with pluggable indexation. This is realized by two interfaces that shall be implemented to provide custom indexation behavior.
org.kie.internal.process.ProcessVariableIndexer
org.kie.internal.task.api.TaskVariableIndexer
details about how to use the indexers can be found in Audit log section of the documentation
QueryService that is an addition to jbpm services, brings in power of Dashbuilder DataSets (SQL based) to jbpm services. This allows more tailored queries that can include both jBPM tables and external tables such as external system data. With this users are in control of what data and how data are going to be queried.
Dashbuilder DataSet introduce concept of building "data base views" for part of the data that can later on be filtered to find relevant data for given invocation.
QueryService is available for all add-ons for services meanign pure java, CDI and EJB.
One of task deadlines actions is notification which by default is implemented as email notification. Although this type of notification does not always fit the requirement. To allow custom notification to be used, jBPM 6.4 was enhanced to support pluggable notification listeners. Notification is realized as broadcast, meaning all available listeners will be invoked, although each listener can decide if it shall react to given notification or not. For instance email notification listener will only send email if it's properly configured (with mail server etc) otherwise it will ignore the notification.
The user can now create a specific filter that provides domain specific columns to be added to a task list. When the user creates a custom filter for a specific task name the task variables are enabled as columns.
The custom filter that activates the capability to display task variables as columns is set a filter with the restriction Name="taskName".
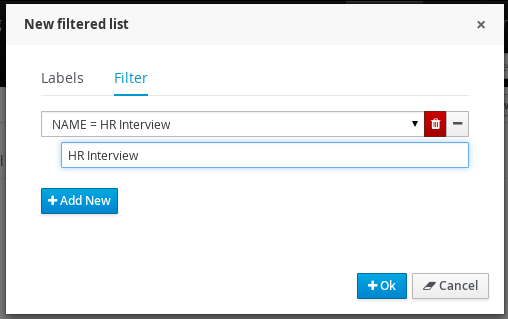
When the filter with the restriction over a specific task name is applied, the task associated variables appear as a selectable columns, to the task list.
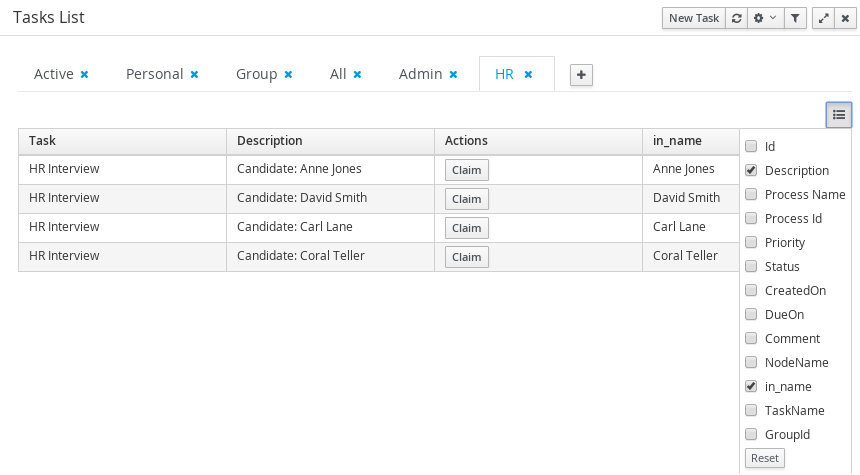
Users are able to view and share process documentation during business process modelling. Process documentation is dynamically updated as users are working on their business process.
Users can print the documentation or view it as a png file.
Process Documentation includes the following sections:
Process Overview (general info, process variables, globals, and imports)
Process Element Details (totals, and specific element information)
Process Image
The general look and feel in the entire workbench has been updated to adopt PatternFly. The update brings a cleaner, lightweight and more consistent user experience throughout every screen. Allowing users focus on the data and the tasks by removing all uncessary visual elements. Interactions and behaviors remain mostly unchanged, limiting the scope of this change to visual updates.
In addition to the PatternFly update described above which targeted the general look and feel, many individual components in the workbench have been improved to create a better user experience. This involved making sure the default size of modal popup windows is appropriate to fit the corresponding content, adjusting the size of text fields as well as aligning labels, and improving the resize behaviour of various components when used on smaller screens.
Locales ru (Russian) and zh_TW (Chineses Traditional) have now been added.
The locales now supported are:
Default English.
es(Spanish)fr(French)de(German)ja(Japanese)pt_BR(Portuguese - Brazil)zh_CN(Chinese - Simplified)zh_TW(Chinese - Traditional)ru(Russian)
The Workbench used to have a section in the Project Editor for "Import Suggestions" which was really a way for Users to register classes provided by the Java Runtime environment to be available to Rule authoring. Furthermore Editors had a "Config" tab which was where Users were expected to import classes from other packages to that in which the rule resides.
Neither term was clear and both were inconsistent with each other and other aspects of the Workbench.
We have changed these terms to (hopefully) be clearer in their meaning and to be consistent with the "Data Object" term used in relation to authoring Java classes within the Workbench.
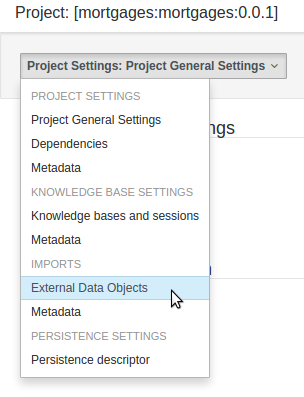
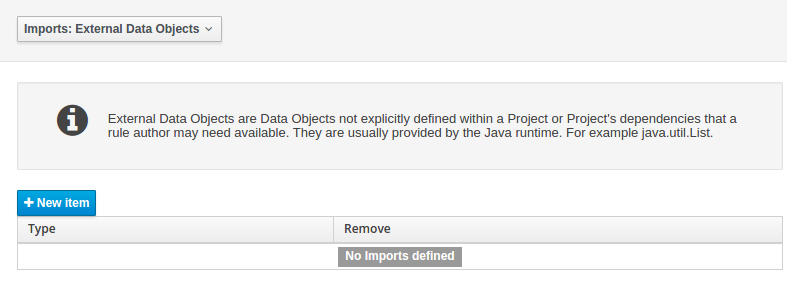
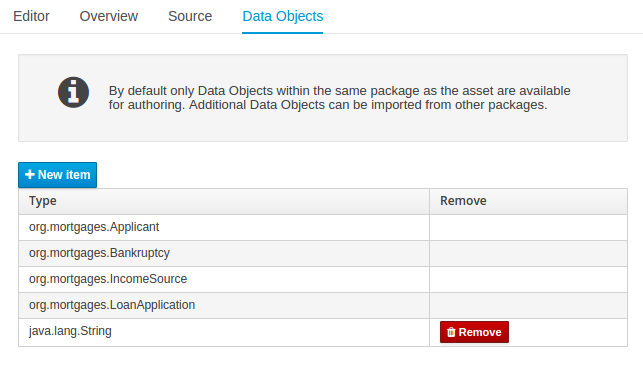
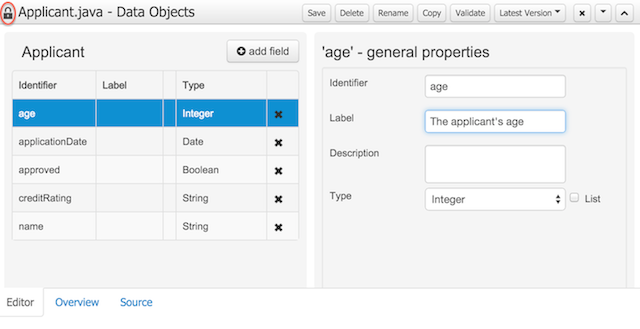
Figure 25.15. Asset Editors - Defining Data Objects available for authoring
The Data Object screen lists all Data Objects in the same package as the asset and allows other Data Objects from other packages to be imported.
When navigating Projects with the Project Explorer the workbench automatically builds the selected project, displaying build messages in the
Message Console. Whilst this is beneficial it can have a detremental impact on performance of the workbench when authoring large projects. The
automatic build can now be disabled with the org.kie.build.disable-project-explorer System Property. Set the value
to true to disable. The default value is false.
When cloning git Repositories it is now possible to use SCP style URLS, for example git@github.com:user/repository.git.
If your Operating System's public keystore is password protected the passphrase can be provided with the org.uberfire.nio.git.ssh.passphrase System Property.
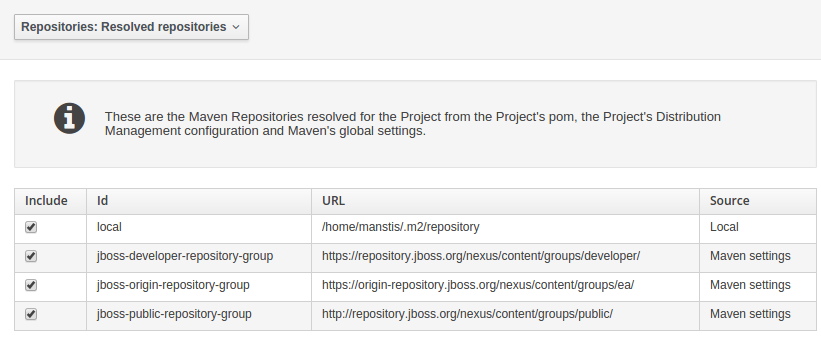
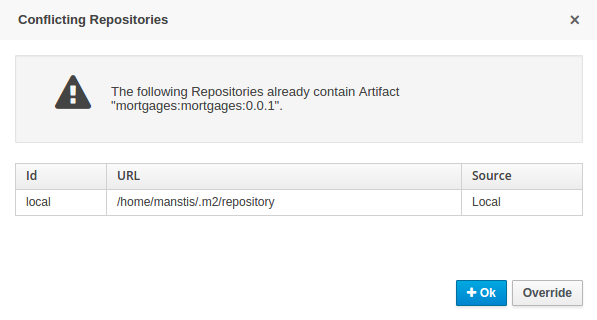
When performing any of the following operations a check is now made against all Maven Repositories, resolved for the Project,
for whether the Project's GroupId, ArtifactId and Version pre-exist. If a clash is found the operation is prevented; although this can be overridden by Users
with the admin role.
Note
The feature can be disabled by setting the System Property org.guvnor.project.gav.check.disabled to true.
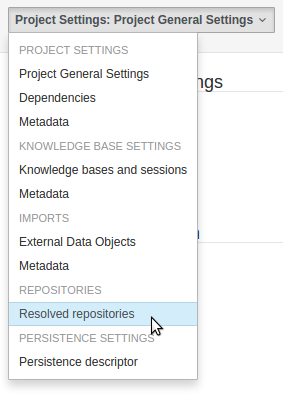
Resolved repositories are those discovered in:-
The Project's
POM<repositories>section (or any parentPOM).The Project's
POM<distributionManagement>section.Maven's global
settings.xmlconfiguration file.
Affected operations:-
Creation of new Managed Repositories.
Saving a Project defintion with the Project Editor.
Adding new Modules to a Managed Multi-Module Repository.
Saving the
pom.xmlfile.Build & installing a Project with the Project Editor.
Build & deploying a Project with the Project Editor.
Asset Management operations building, installing or deploying Projects.
RESToperations creating, installing or deploying Projects.
Users with the Admin role can override the list of Repositories checked using the "Repositories" settings in the Project Editor.
The KIE Execution Server Management UI has been completely redesigned to adjust to major improvements introduced recently. Besides the fact that new UI has been built from scratch and following best practices provided by PatternFly, the new interface expands previous features giving users more control of their servers.
Provides the backend services and an intuitive and friendly user interface that allows the workbench administrators to manage the application's users and groups.
This interface provides to the workbench administrators the ability to perform realm related operations such as create users, create groups, assign groups or roles to a given user, etc.
It comes by default with built-in implementations for the administration of Wildfly, EAP and Tomcat default realms, and it's designed to be extensible - any third party realm management system can be easily integrated into the workbench.
The following features were added to jBPM 6.3.
JavaScript as script language
You can now use JavaScript as dialect in scripts (script task and on-entry and on-exit scripts) and for constraints (for example on gateways). Same as with the Java and MVEL dialect, you have direct access to variables, globals and to the kcontext variable (giving you access to the ProcessContext).
For example, you can write something like:
kcontext.setVariable('surname', "tester"); var text = 'Hello '; print(text + kcontext.getVariable('name') + '\n'); try { somethingInvalid; } catch(err) { print(err + '\n'); }
Async continuation
Async continuation simplifies usage of asynchronous processing of process activities. Simply marking process activity as async will instruct the engine to complete current processing (including committing transaction) before entering that activity. This in turn will allow more control over what is executed in sequence and improve overall managebility of process execution. Here you can read an article describing this in details.
Signal scopes
Version 6.3 comes with improved support for signaling process instances. Based on concepts of singals defined in BPMN2 jBPM provides additional characteristic to them - the scope. Scope defines how to propagate the signal:
process instance scope - signals only elements within the same process instance, other process isntances won't be affected
default (ksession) scope - signals all elements that are waiting for given signal and are known to running ksession
project scope - signals all components within given project (that means managed by the same instance of runtime manager)
external scope - pluggable scope that allow to customize signal propagation - jBPM 6.3 comes with JMS based implementation which is enabled in workbench (receiving part)
More about the improved signaling can be found in this article.
Improved search capabilities when using jbpm services (RuntimeDataService) that allows
search by correlation key
search by process variable name
search by process variable name and value
Throw async signals
If there are several process instances from different process definitions, all of them waiting the same signal and only one of these process instances throws a RuntimeException all others not related will not move forward as well, because they are executed sequentially in the same transaction. That creates heavy dependency between unrelated process instances. Asynchronous throw event solves the problem by individually signaling each process instance in background.
The core process engine has always contained the flexibility to model adaptive and flexible processes. These kinds of features are typically also required in the context of case management. To simplify picking up some of these more advanced features, we created a (wrapper) API that exposes some of these features in a simple API. Note that this API simply relies on other existing features / API and can easily be extended. The API and implementation is added as part of a new jbpm-case-mgmt module.
Process instance description
Each case can have a unique name, specific to that case.
Case roles
A case can keep track of who is participating by using case roles. These roles can be defined as part of the case definition (by giving them a name and (optionally) a cardinality). Case roles could also be defined dynamically (at runtime). For active case instances, specific users can be assigned to roles.
Ad-hoc cases
One can start a new case without even having a case definition. Whatever happens inside this case is completely determined at runtime.
Case file
A case can contain any kind of data, from simple key-value pairs to custom data objects or documents.
Ad-hoc tasks
Using the ad-hoc constructs available in BPMN2, one can model optional process fragments, where only at runtime it is decided which of these fragments should be executed (and how many times). This could be driven by end users (selecting optional fragments for execution) or automatically (for example by rules that trigger certain fragments under certain conditions, or whenever triggered by external services).
Dynamic tasks
It is possible to add new tasks dynamically, even if they weren't defined upfront (in the case definition). This includes human tasks, service tasks and other processes.
Milestones
You can define milestones as part of the case definition (or even dynamically) and keep track of which milestones were reach for specific case instances.
The remote REST API for accessing the workbench received the following extensions:
Process instance image
Through the remote REST API you can now retrieve an image that represents the status of a particular process instance, annotated on the process diagram. This will generate the same image as you could already see in the workbench by looking at the process instance diagram, i.e. active nodes will be marked with a red border and completed nodes have a gray background. This is generated based on the SVG of the process diagram, which can automatically be generated by designer whenever saving a process.
Note
A newSVGImageProcessorhas been used to add the necessary annotations based on the audit log data. Note that this processor (in thejbpm-process-svgmodule) could be extended to support more advanced visualizations.This feature is unfortunately not active by default! In order to activate this feature, it is necessary to follow the following steps:
- Open the
org.kie.workbench.KIEWebapp/profiles/jbpm.xmlfile in the kie-wb war. Towards the top of this
jbpm.xmlfile, you'll see the following xml element:<storesvgonsave enabled="false"/>Change the
falsevalue here totrue.- (Re)Deploy the war
Furthermore, only process definitions that have been opened in the designer after this modification will be available via the REST operations described below. However, providing process images by default via REST (without having to turn on an option or open the process definition in designer) is on the roadmap.
2 new REST operation URLs have been made available to provide the image:
The following URL provides an image of the process definition:
{server}/jbpm-console/rest/runtime/{deploymentId}/process/{processDefId}/imageThe
deploymentIdURL parameter corresponds to the deployment id, while theprocessDefIdparameter corresponds to the process (definition) id.The following URL provides an image of the process definition, with the active nodes marked to correspond to the process instance URL parameter passed:
{server}/jbpm-console/rest/runtime/{deploymentId}/process/{processDefId}/image/{procInstId}The
deploymentIdURL parameter corresponds to the deployment id, theprocessDefIdparameter corresponds to the process (definition) id, and theprocInstIdURL parameter corresponds to the process instance id.
- Open the
The remote clients - kie-remote-client for accessing the workbench embedded in the workbench and kie-server-client for the separate (unified) execution server - are now also available as an OSGi feature.
jBPM Designer includes a new dialog for editing data inputs and outputs on activities in Business Processes. The dialog combines the functions of the dialogs in previous versions of jBPM Designer for editing data inputs and outputs, and for defining assignments between data inputs/outputs and process variables. The dialog allows the user to:
create and edit data inputs and data outputs on activities
define assignments from process variables or constants to data inputs, and from data outputs to process variables
The dialog is accessed by editing the Assignments property for activities which have this property, such as User Tasks, or by editing the DataInputAssociations or DataOutputAssociations property for activities which have one of these properties. The dialog is also available by clicking on a new button associated with those activities for which it is relevant:

jBPM executor has been significantly enhanced in version 6.3 where the biggest improvement was to provide support for JMS based notification mechanism to improve performance for immediate job execution. Instead of always relying on poll based mechanism, in case of immediate job request the executor is notified via JMS. Though it still provides same set of capabilities:
retry mechanism
error handling
search capabilities to look through job requests
Retry mechanism was static in prior versions, which means that the retry happened directly with next execution cycle. That made it rather low in terms of usage as in case there was a temporary problem e.g. network issue, system not available. It has been improved as well and allows configurable retry delay to be specified on each job individually. This delay can be given as time expressions that will be calculated from current time stamp. Retry delay can be given as:
single time expression - 5m or 2h
comma separated list of time expressions that should be used for subsequent retries - 10s,10m,1h,1d
In case number of retry delays is smaller than number of retries it will use last available value from the list of retry delays. Which for single value means it will always be the same value.
More information about executor enhancements can be found in these two articles: Shift gears with jBPM executor and Asynchronous processing
jBPM 6.3 brings in fully featured Unified KIE Execution Server that is based on successful KIE Execution Server that was released with 6.2 and covered rules use case. In 6.3 this execution server has ben enhanced and now support for rules and process (including user tasks and asynchronous jobs). It provides lightweight mechanism for executing your business assets. Number of environments can be built with with it:
single execution server (similar to workbench)
execution server per kjar
execution server per domain knowledge (set of kjars)
and more...
It is prepared to run on almost any container where tested configuration include following:
JBoss EAP 6.4
Wildfly 8.1 and 8.2
Tomcat 7 and 8
WebSphere 8.5.5.x
Weblogic 12c
To get started with KIE Execution Server look at this blog series that provides KIE Execution Server introduction.
The process and task lists screens are now backed up by the Dashbuilder's DataSet APIs and data providers. This enable these runtime screens to retrieve the data in a much more efficient way and enable the users to apply more advanced filters.
The initial version for creating filters is provided with jBPM 6.3.0.Final and it will be extended and polished in future versions.
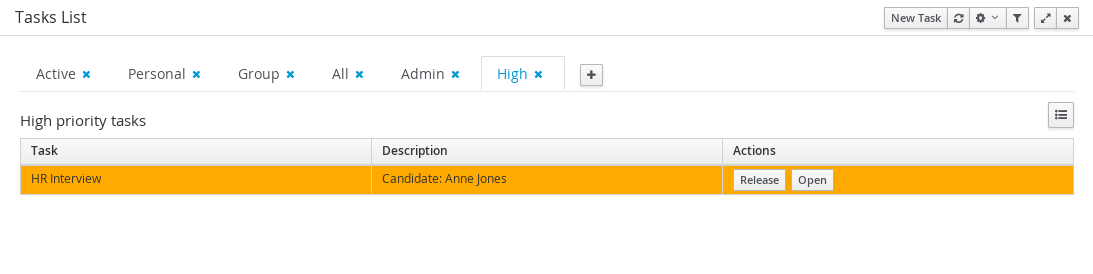
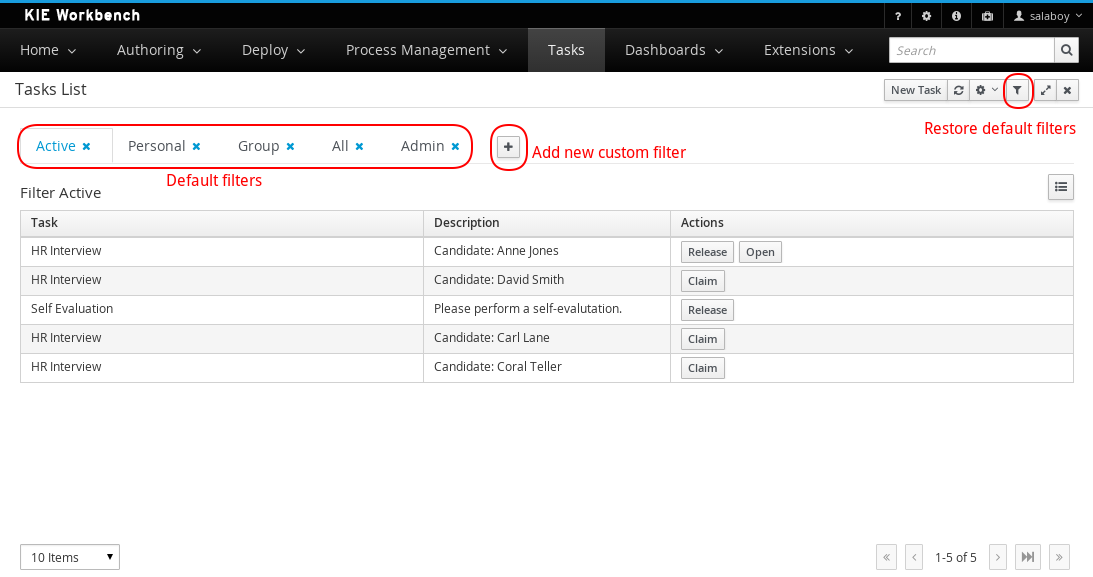
A new button to restore the default filters if needed is provided.
New filters can be created using the + button. This enable users to have custom filters. There is one filter per tab.
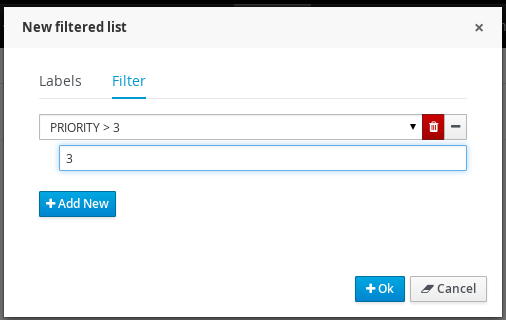
Users can create as many custom filters as they want. These filters will be stored in the user preferences.
The process instance list now provides domain specific columns to be added in custom filters. When the user creates a custom filter for a specific process definition the process variables are enabled as columns, to the process instance list. This feature wil be added to the task list as well in future versions.
Note
Only Process Variables with values will be listed in the column picker inside the custom filter tab.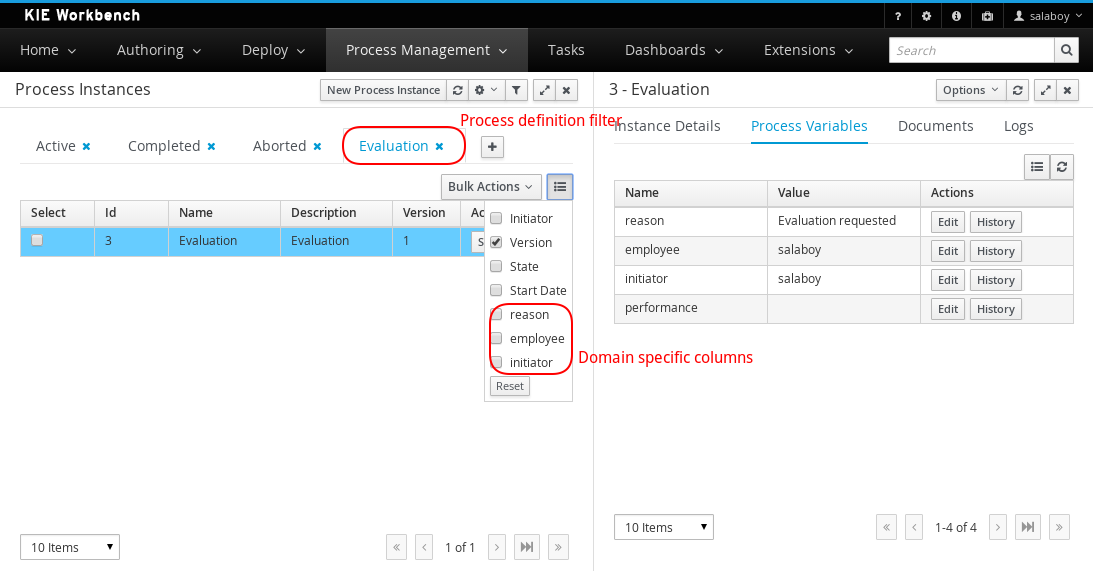
Decision tables used to have a Validation-button for validating the table. This is now removed and the table is validated after each cell value change. The validation and verification checks include:
- Redundancy
- Subsumption
- Conflicts
- Missing Columns
These checks are explained in detail in the workbench documentation.
The DRL Editor has undergone a face lift; moving from a plain TextArea to using ACE Editor and a custom DRL syntax highlighter.
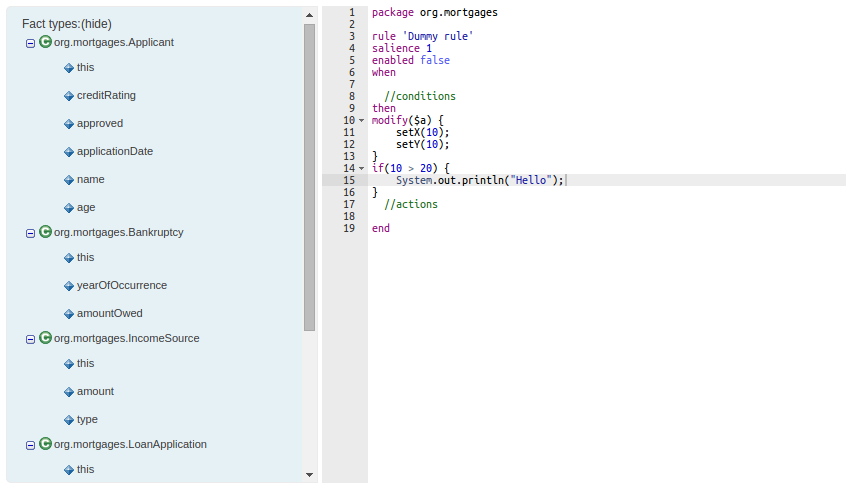
To avoid conflicts when editing assets, a new locking mechanism has been introduced that makes sure that only one user at a time can edit an asset. When a user begins to edit an asset, a lock will automatically be acquired. This is indicated by a lock symbol appearing on the asset title bar as well as in the project explorer view. If a user starts editing an already locked asset a pop-up notification will appear to inform the user that the asset can't currently be edited, as it is being worked on by another user. As long as the editing user holds the lock, changes by other users will be prevented. Locks will automatically be released when the editing user saves or closes the asset, or logs out of the workbench. Every user further has the option to force a lock release in the metadata tab, if required.
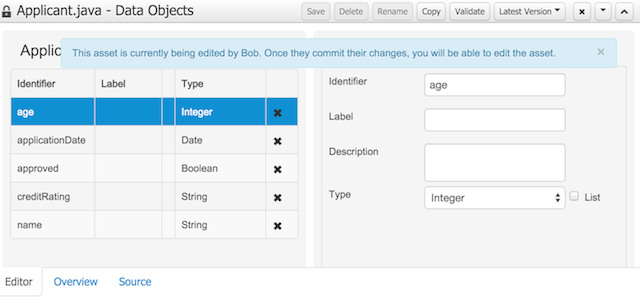
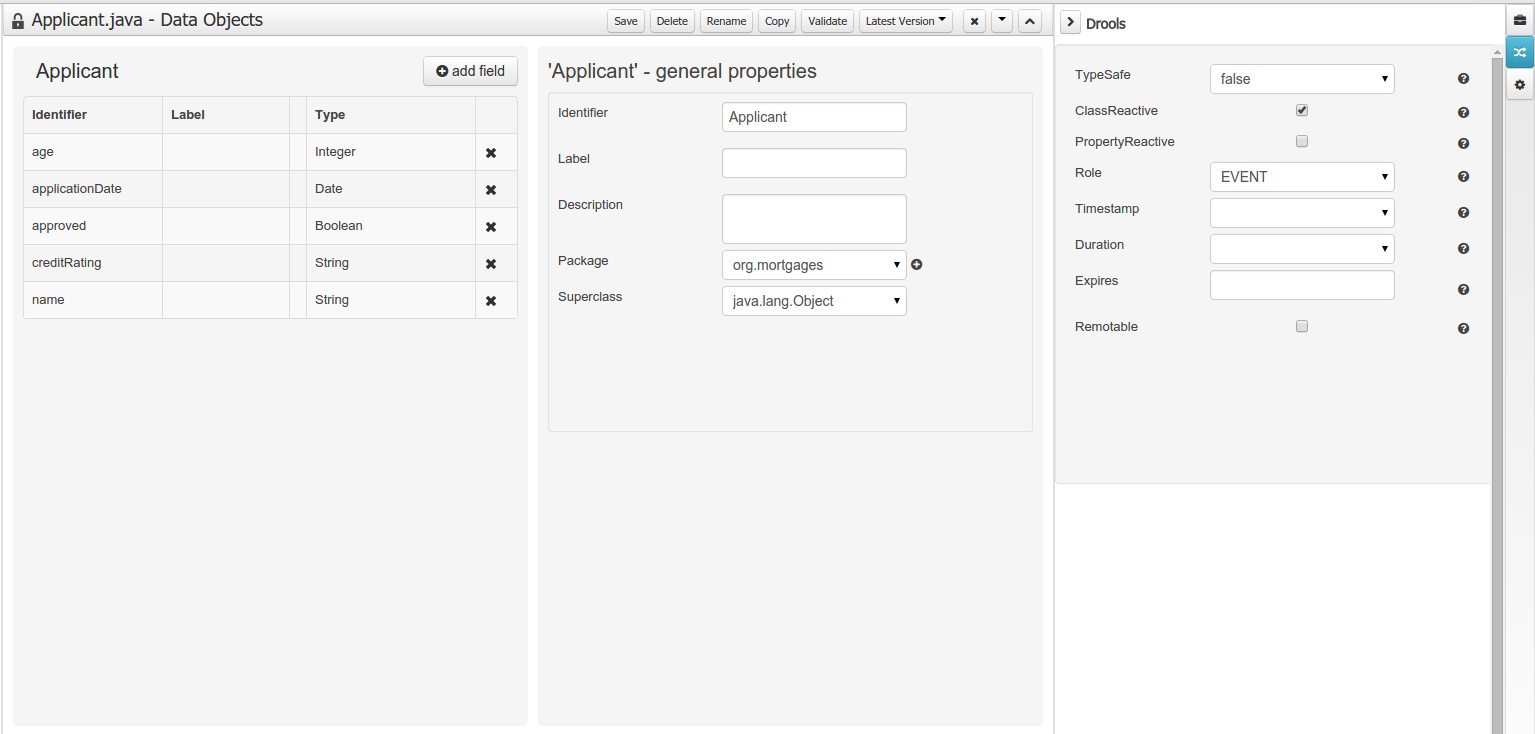
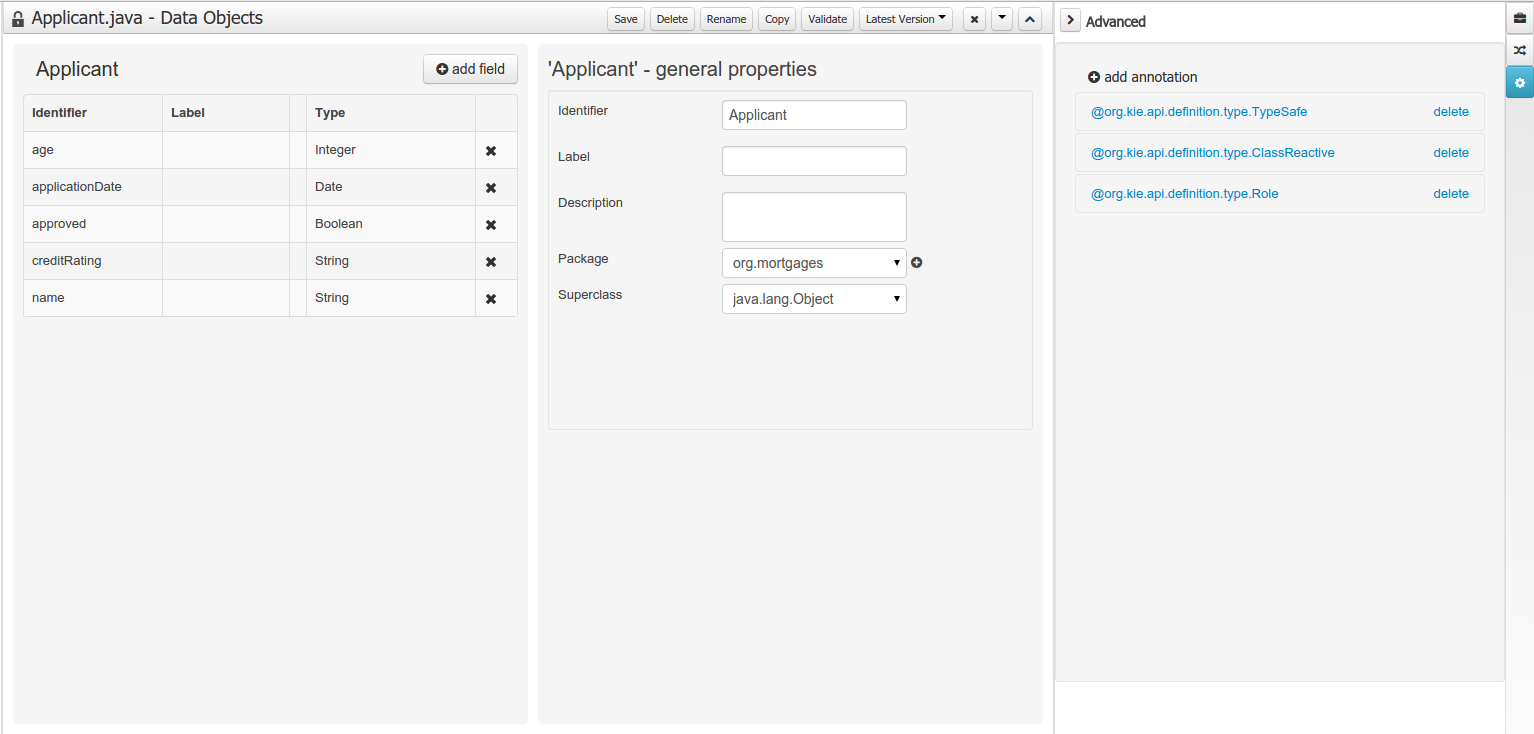
Drools and jBPM configurations, Persistence (see Generation of JPA enabled Data Models) and Advanced configurations were moved into "Tool Windows". "Tool Windows" are a new concept introduced in latest Uberfire version that enables the development of context aware screens. Each "Tool Window" will contain a domain editor that will manage a set of related Data Object parameters.
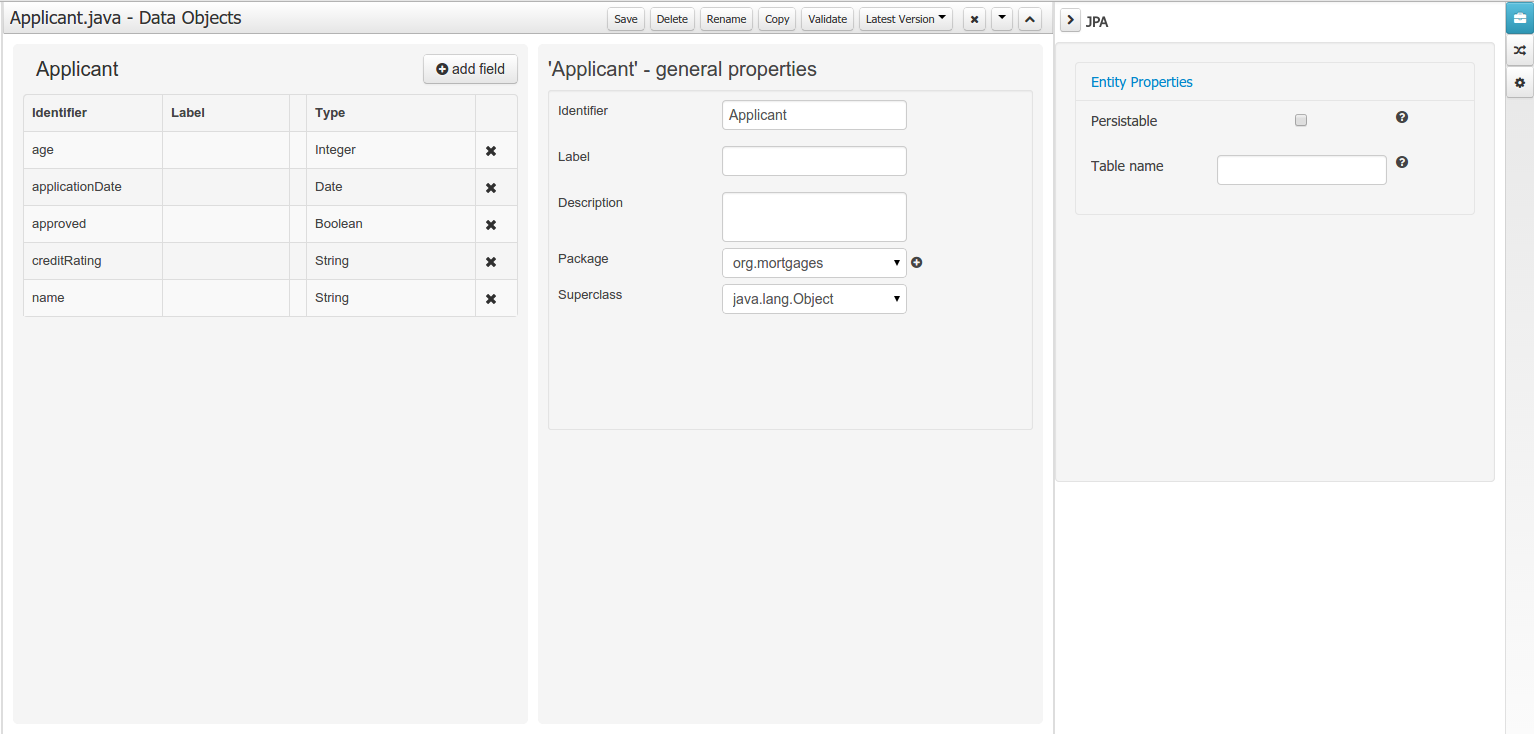
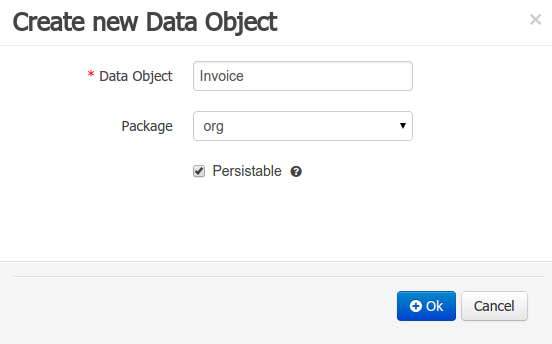
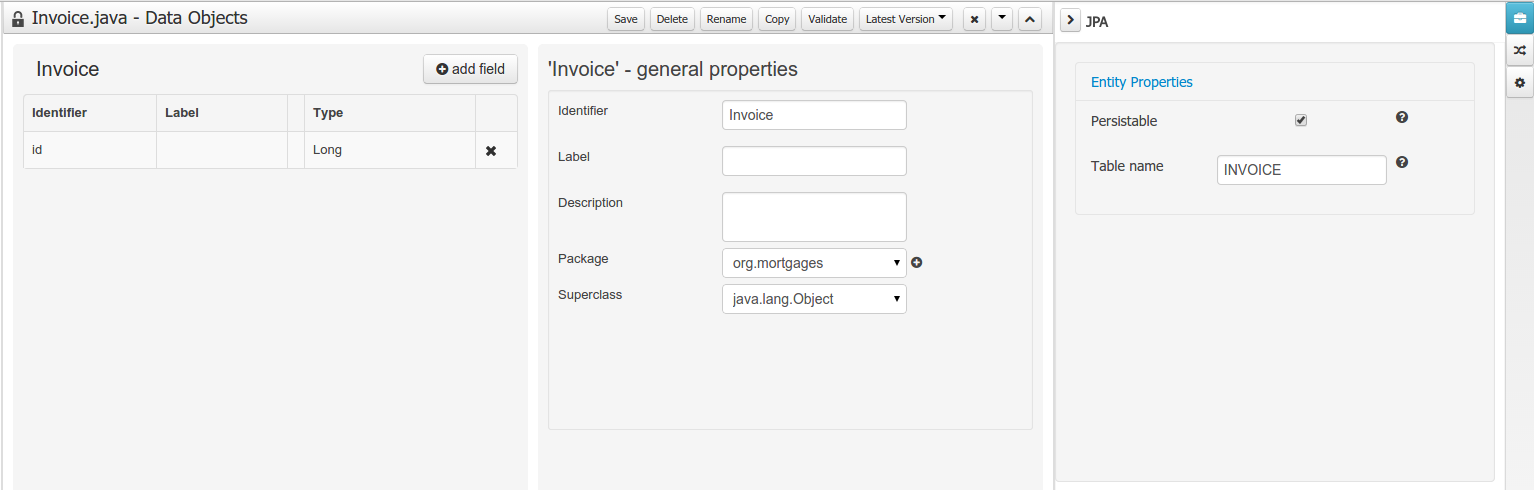
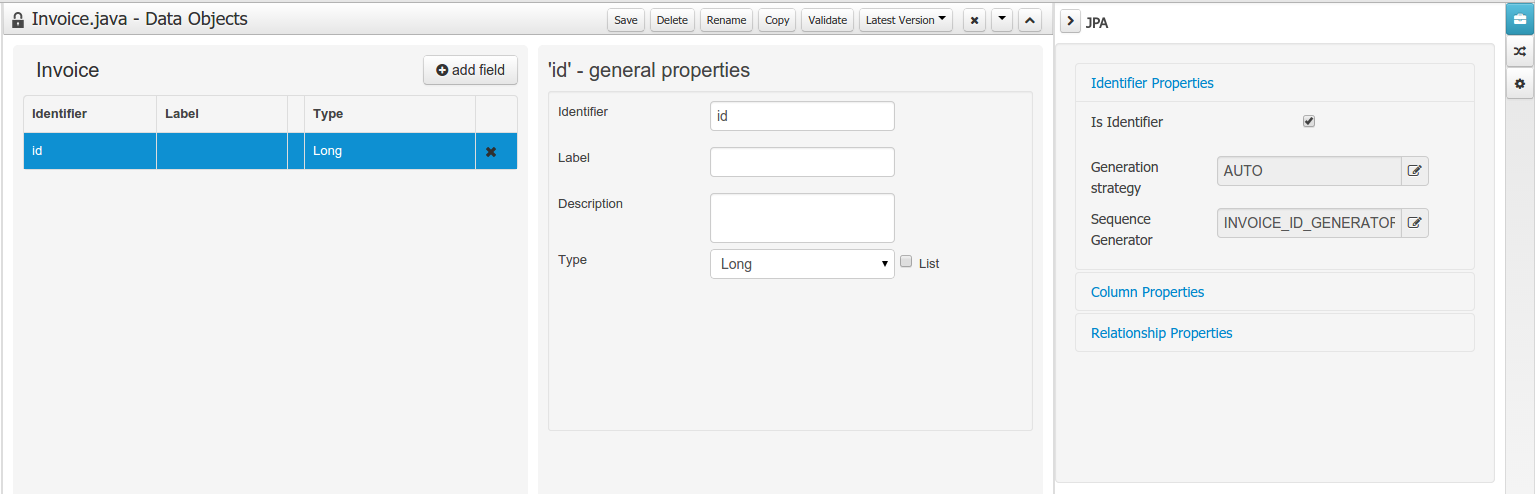
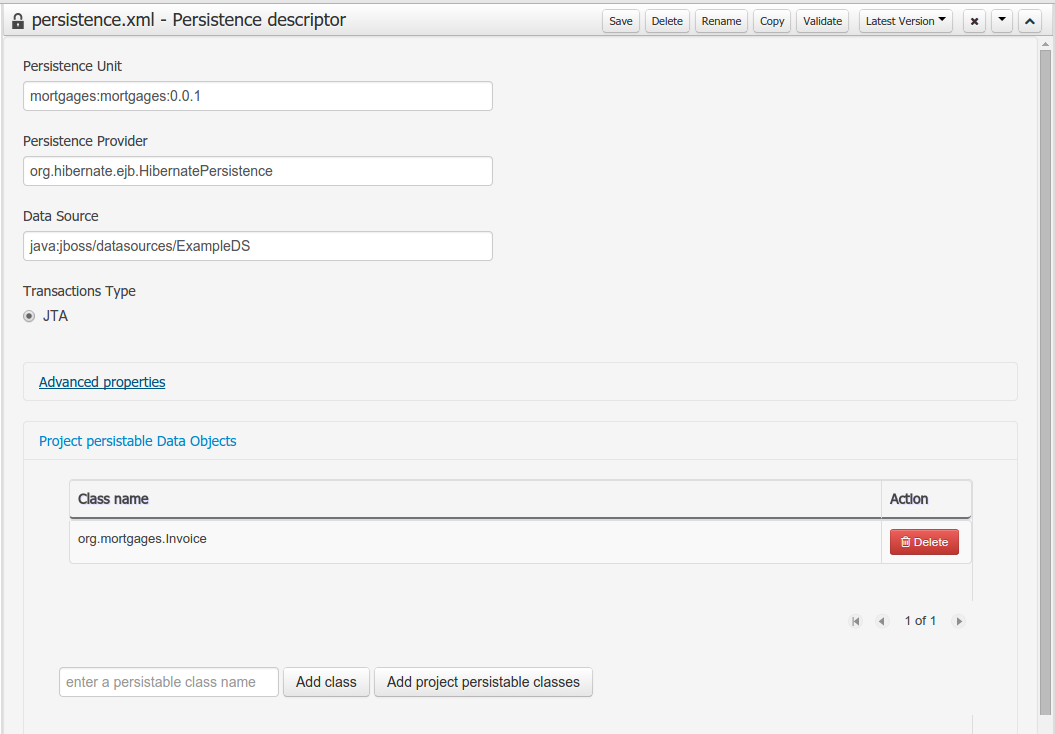
Data modeller was extended to support the generation of persistable Data Objects. The persistable Data Objects are based on the JPA specification and all the underlying metadata are automatically generated.
"The New -> Data Object" Data Objects can be marked as persistable at creation time.
The Persistence tool window contains the JPA Domain editors for both Data Object and Field. Each editor will manage the by default generated JPA metadata
Persistence configuration screen was added to the project editor.
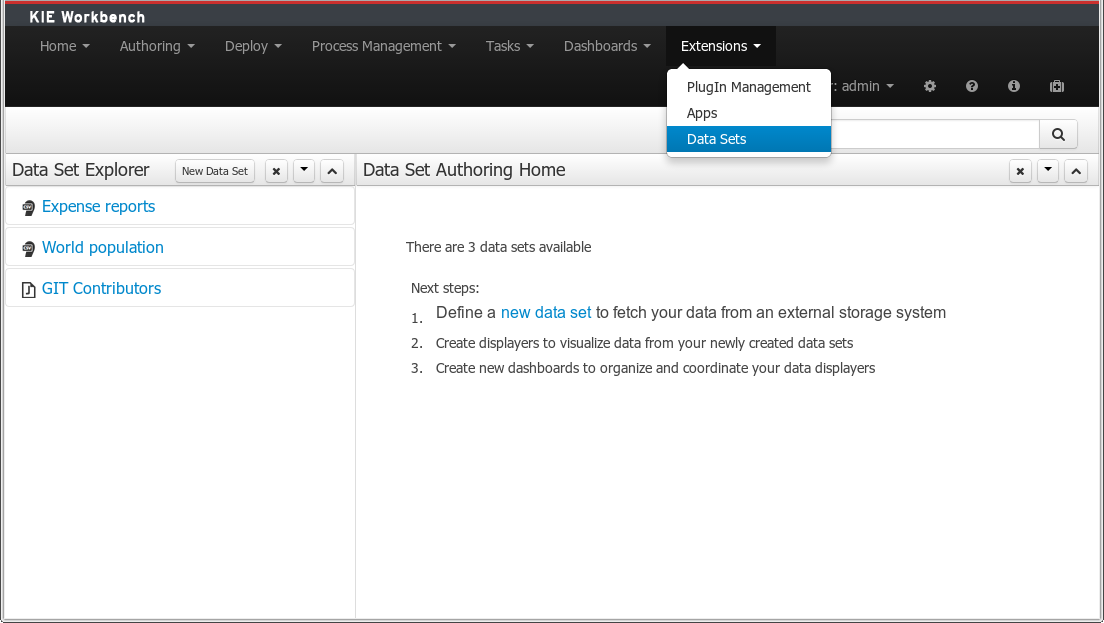
A new perspective for authoring data set definitions has been added. Data set definitions make it possible to retrieve data from external systems like databases, CSV/Excel files or even use a Java class to generate the data. Once the data is available it can be used, for instance, to create charts and dashboards from the Perspective Editor just feeding the charts from any of the data sets available.
The following features were added to the jBPM core on top of 6.1.
jBPM services modules have been significantly refactored to provide clear separation between the logic they bring and various frameworks that can be used to consume those services. With version 6.2 following modules are available:
jbpm-services-api - clear services api that shall be used by any client code that consumes services
jbpm-kie-services - core implementation of the services that do not have any framework specific code (e.g. CDI)
jbpm-services-cdi - CDI specific code on top of jbpm-kie-services
jbpm-services-ejb-api - ejb related extensions to services api - mainly to provide remote capablities for the interfaces
jbpm-services-ejb-impl - ejb specific code on top of jbpm-kie-services
jbpm-services-ejb-client - ejb client implementation to interact with services over remote ejb invocation - currently JBoss specific implementation available
jbpm-service-ejb-timer - ejb timer service backed by JEE timer service provided by container
jBPM services are intended to be base of execution server (regardless of what framework is used to build it up completely) so should be considered as first choice when enbedding jbpm in custom applications. With 6.2 capabilities it already provides support for most common frameworks used - CDI, EJB, Spring (should simply rely on core implementation). See this article for details and example.
Lazy initialization of runtime engine components by RuntimeManager to make runtime engine creation lightweight
RuntimeEngine has been enhanced to lazy initialize its components (KieSession, TaskService, AuditService) to improve overall performance of retriveing RuntimeEngine instances from RuntimeManager.
Life cycle management for work item handlers and event listeners
Handler and listeners can implement additional interface to be managed by runtime engine, see work item handler life cycle management for more details.
Deployments are now by default stored in data base (as deployment descriptors) to servive server restarts
Prior to verion 6.2 deployments that were handled by DeploymentService implementation were not persisted so they required to be handled separately - in case of kie-workbench they were stored inside system.git repo. With version 6.2 deployment service will persist that information directly into db which will make it easier in many cases including clustering as it will not require VFS clustering (Zookeeper and Helix) setup.
Extension to deployment descriptor to specify classes (by FQCN) that should be added to JAXB context for remote interfaces interaction
Deployment descriptor accept new set of elements
<remoteable-classes> ... <remotable-class>org.jbpm.test.CustomClass</remotable-class> ... </remoteable-classes>Classpath scanning for classes to be included in JAXB context for remote interfaces interaction
Classes annotated with javax.xml.bind.annotation.XmlRootElement and org.kie.api.remote.Remotable will be automatically added to JAXB context of given deployment as soon as they are defined as project dependency. At the same time all classes included in project itself are also added to deployment's JAXB context.
jbpm executor has been enhanced to provide support for:
requeue failed jobs so they can be executed once the error that caused them to is resolved.
reoccuring jobs that allows single definition to be repeatedly invoked based on time intervals, e.g. daily jobs to clean up history log tables. See this article for details and example.
CRON support for intermediate and boundary timer events
Enhanced support for multi instance activities to support completion condition as MVEL expression
While a number of core jars were OSGi-ready (in v5 already), a significant number of additional jars were now added to this list, including for example the human task service, the runtime managers, full persistence, etc. As a result, full core engine functionality is now available on top of OSGi. Specific extensions and tests showing it in action are available for Apache Karaf and Aries Blueprint (in the droolsjbpm-integration repository).
A new out-of-the-box service task has been implemented for using Apache Camel to connect a process to the outside world using some of the numerous Camel endpoint URIs. The service task allows you to for example specify how to pass data to an FTP endpoint by configuring properties such as hostname, port, username, payload, etc. for some common endpoints like (S)FTP, File, JMS, XSLT, etc. but you can use virtually any of the available endpoints by defining the URI yourself (http://camel.apache.org/uris.html).
Support for JavaScript code:
Added field property on simple fields to allow the user to add JavaScript code on the onchange event. This will allow the user to add richer functionallities on the forms.
Simplified the autogenerated field id's in order to allow the user to access the inputs directly via JavaScript.
New field types:
Added configurable ComboBox and RadioGroup fields. This new fields types allow the user to add ComboBoxes and Radio Button groups selecting their data source from the list of the Sources registered on the application.
Added support to simple types Lists (java.util.List<String>, java.util.List<Integer>, java.util.List<Long>...). This fields allow the user to upload multiple basic values (strings, numbers, dates and booleans) storing them on java.util.List
This feature makes it possible to download a repository or a folder from the repository as a ZIP file.
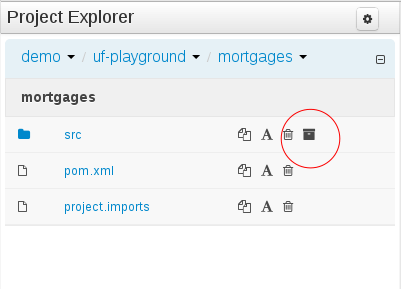
The ability to configure role-based permissions for the Project Editor have been added.
Permissions can be configured using the WEB-INF/classes/workbench-policy.properties file.
The following permissions are supported:
Save button
feature.wb_project_authoring_saveDelete button
feature.wb_project_authoring_deleteCopy button
feature.wb_project_authoring_copyRename button
feature.wb_project_authoring_renameBuild & Deploy button
feature.wb_project_authoring_buildAndDeploy
All of our new screens use GWT-Bootstrap widgets and alert users to input errors in a consistent way.
One of the most noticable differences was the Guided Decision Table Wizard that alerted errors in a way inconsistent with our use of GWT-Bootstrap.
This Wizard has been updated to use the new look and feel.
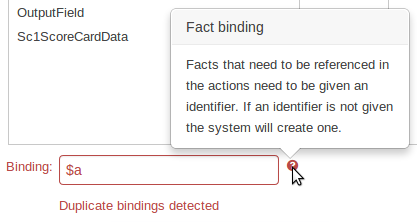
During the re-work of the Guided Decision Table's Wizard to make it's validation consistent with other areas of the application we took the opportunity to move the Wizard Framework to GWT-Bootstrap too.
The resulting appearance is much more pleasing. We hope to migrate more legacy editors to GWT-Bootstrap as time and priorities permit.
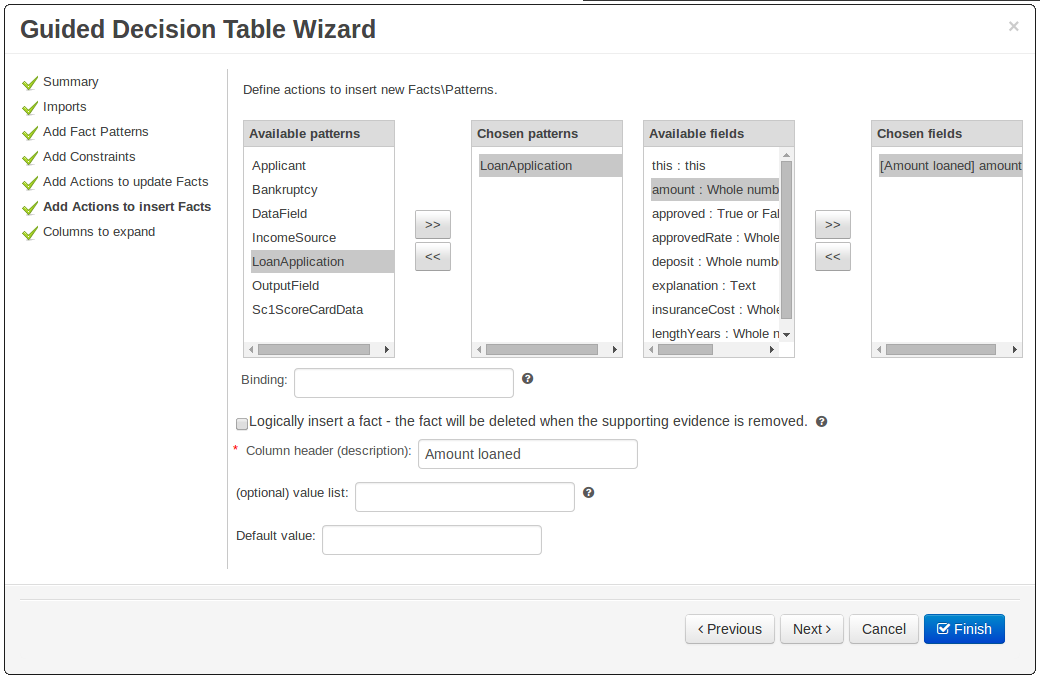
Consistency is a good thing for everybody. Users can expect different authoring metaphores to produce the same rule behaviour (and developers know when something is a bug!).
There were a few inconsistencies in the way XLS Decision Tables, Guidied Decision Tables and Guided Rule Templates generated the underlying rules for empty cells. These have been eliminated making their operation consistent.
If all constraints have null values (empty cells) the Pattern is not created.
Should you need the Pattern but no constraints; you will need to include the constraint
this != null.This operation is consistent with how XLS and Guided Decision Tables have always worked.
You can define a constraint on a String field for an empty String or white-space by delimiting it with double-quotation marks. The enclosing quotation-marks are removed from the value when generating the rules.
The use of quotation marks for other String values is not required and they can be omitted. Their use is however essential to differentiate a constraint for an empty String from an empty cell - in which case the constraint is omitted.
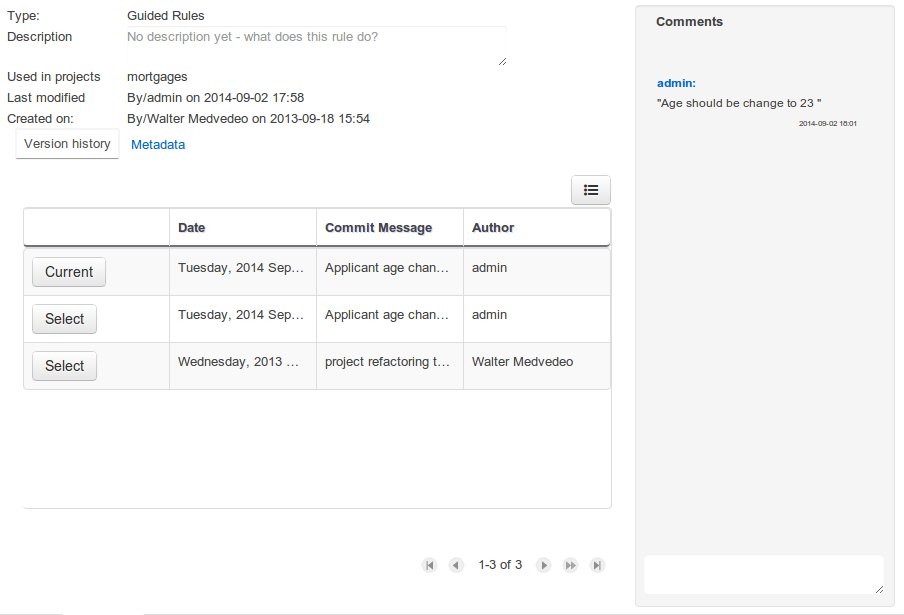
The Metadata tab provided in previous versions was redesigned to provide a better asset versioning information browsing and recovery. Now every workbench editor will provide an "Overview tab" that will enable the user to manage the following information.
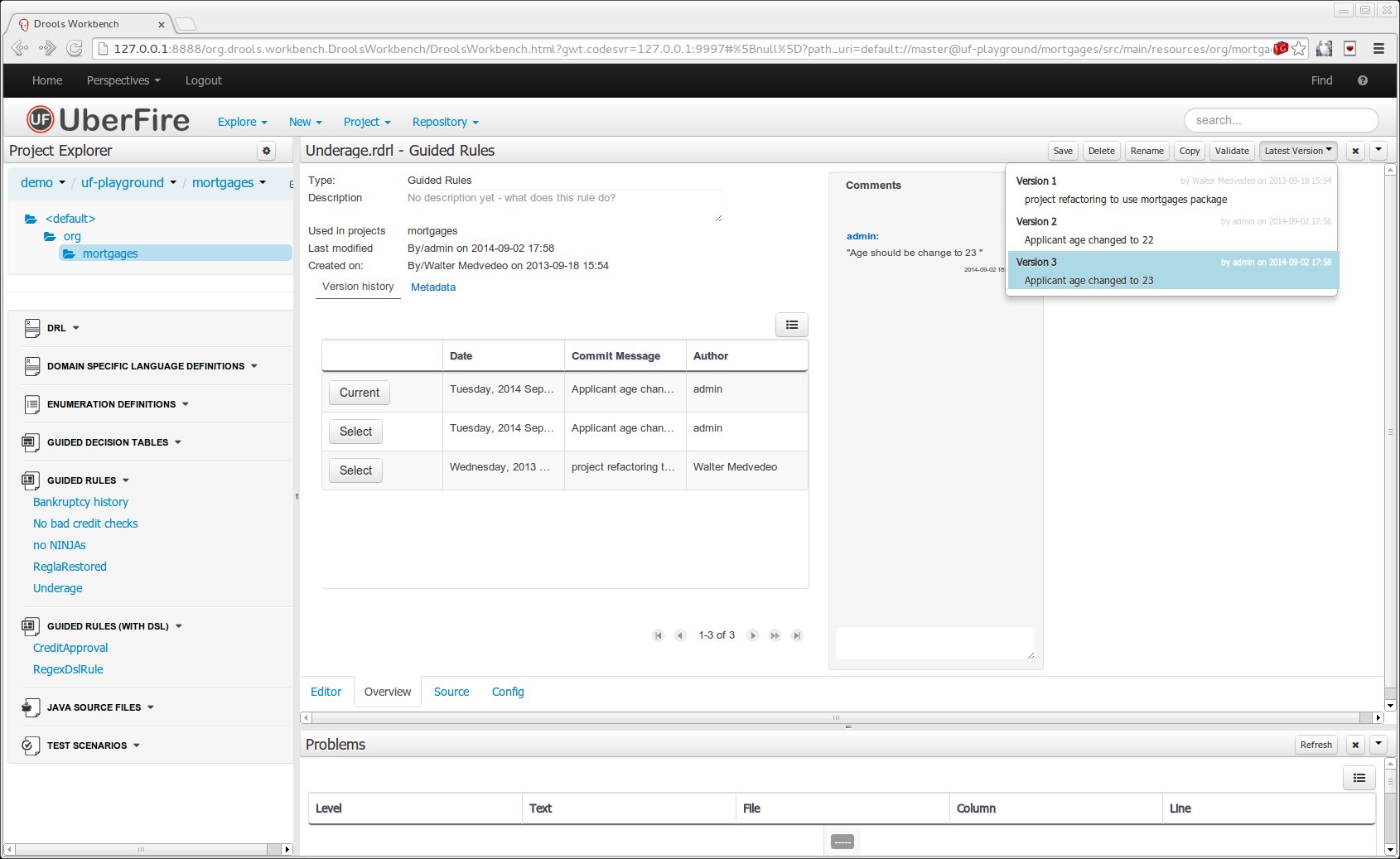
Versions history
The versions history shows a tabular view of the asset versions and provides a "Select" button that will enable the user to load a previously created version.
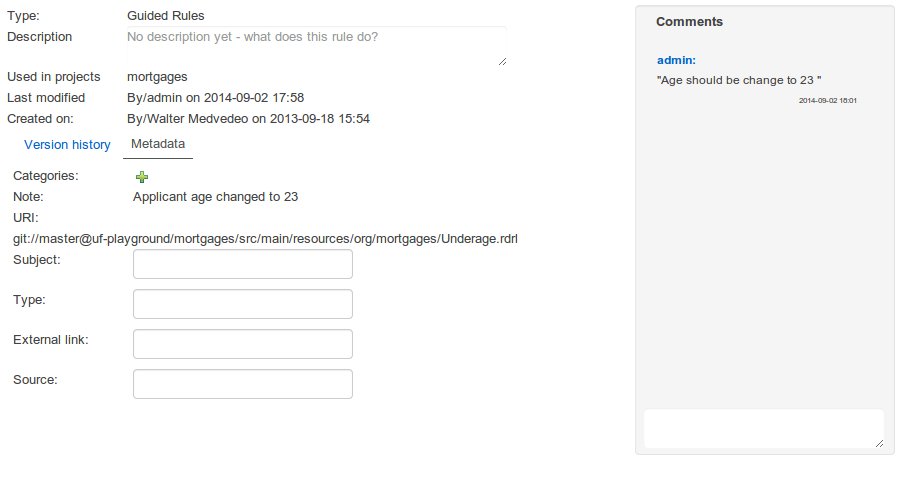
Metadata
The metadata section gets access to additional file attributes.
Comments area
The redesigned comments area enables much clearer discussions on a file.
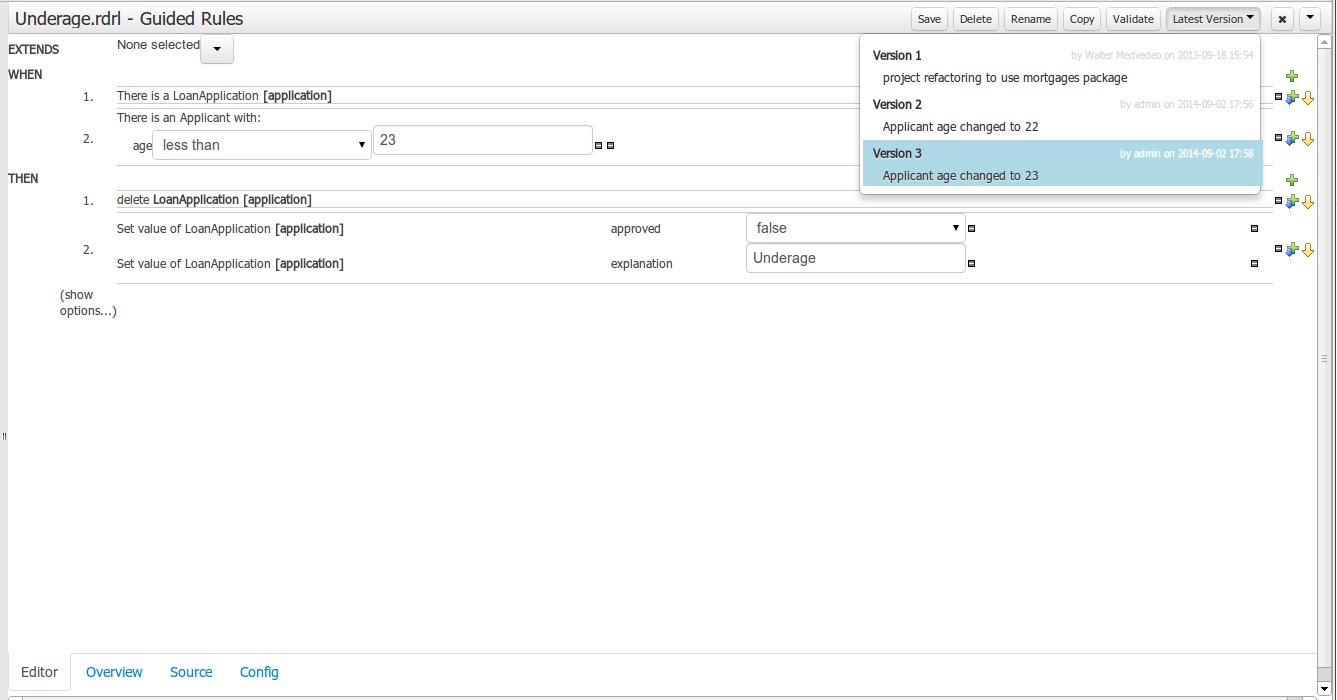
Version selection dropdown
The "Version selector dropdown" located at the menu bar provides the ability to load and restore previous versions from the "Editor tab", without having to open the "Overview tab" to load the "Version history".
The Java editor was unified to the standard workbench editors functioning. It means that and now every data object is edited on his own editor window.
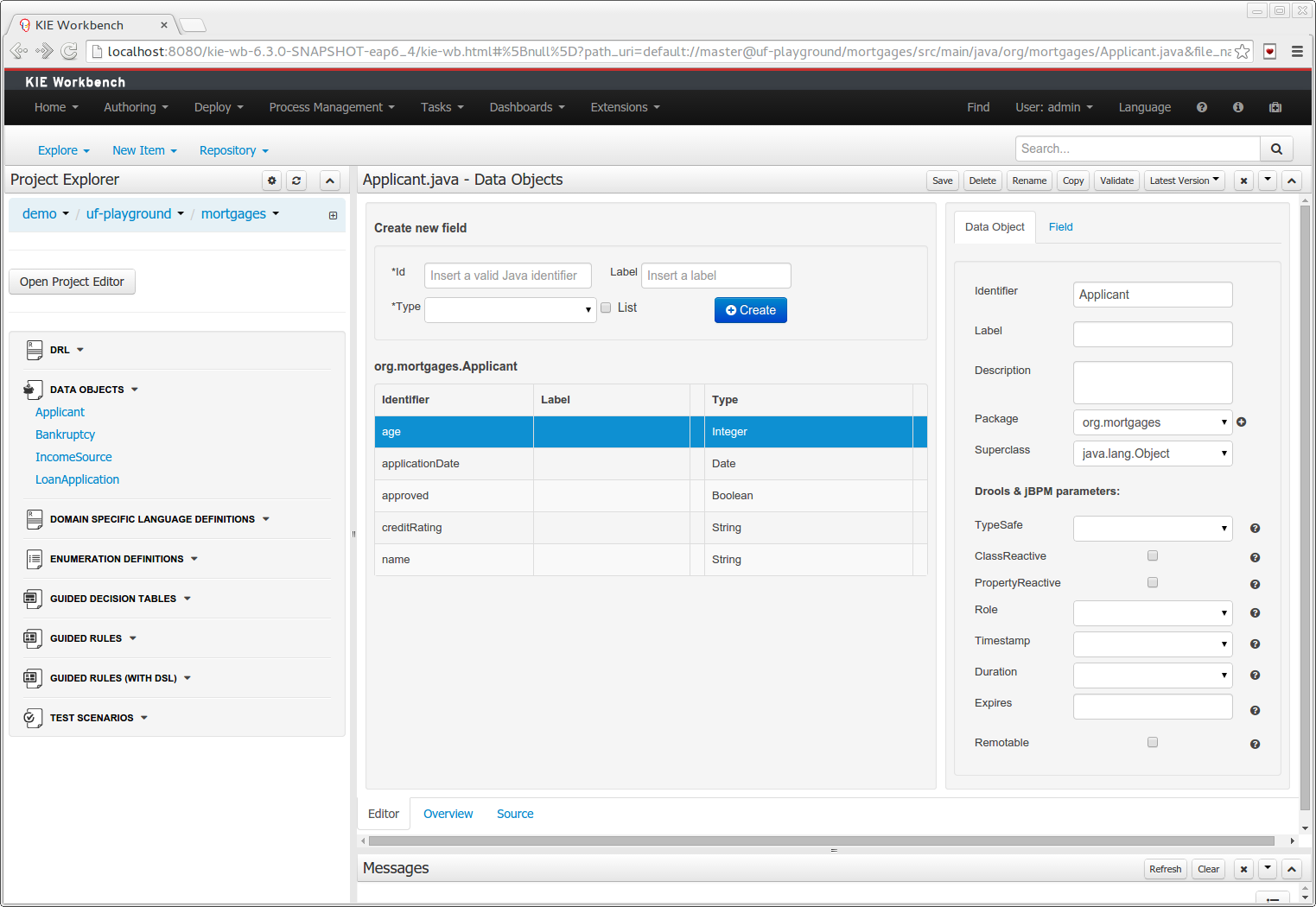
"New -> Data Object" option was added to create the data objects.
Overview tab was added for every file to manage the file metadata and have access to the file versions history.
Editable "Source Tab" tab was added. Now the Java code can be modified by administrators using the workbench.
"Editor" - "Source Tab" round trip is provided. This will let administrators to do manual changes on the generated Java code and go back to the editor tab to continue working.
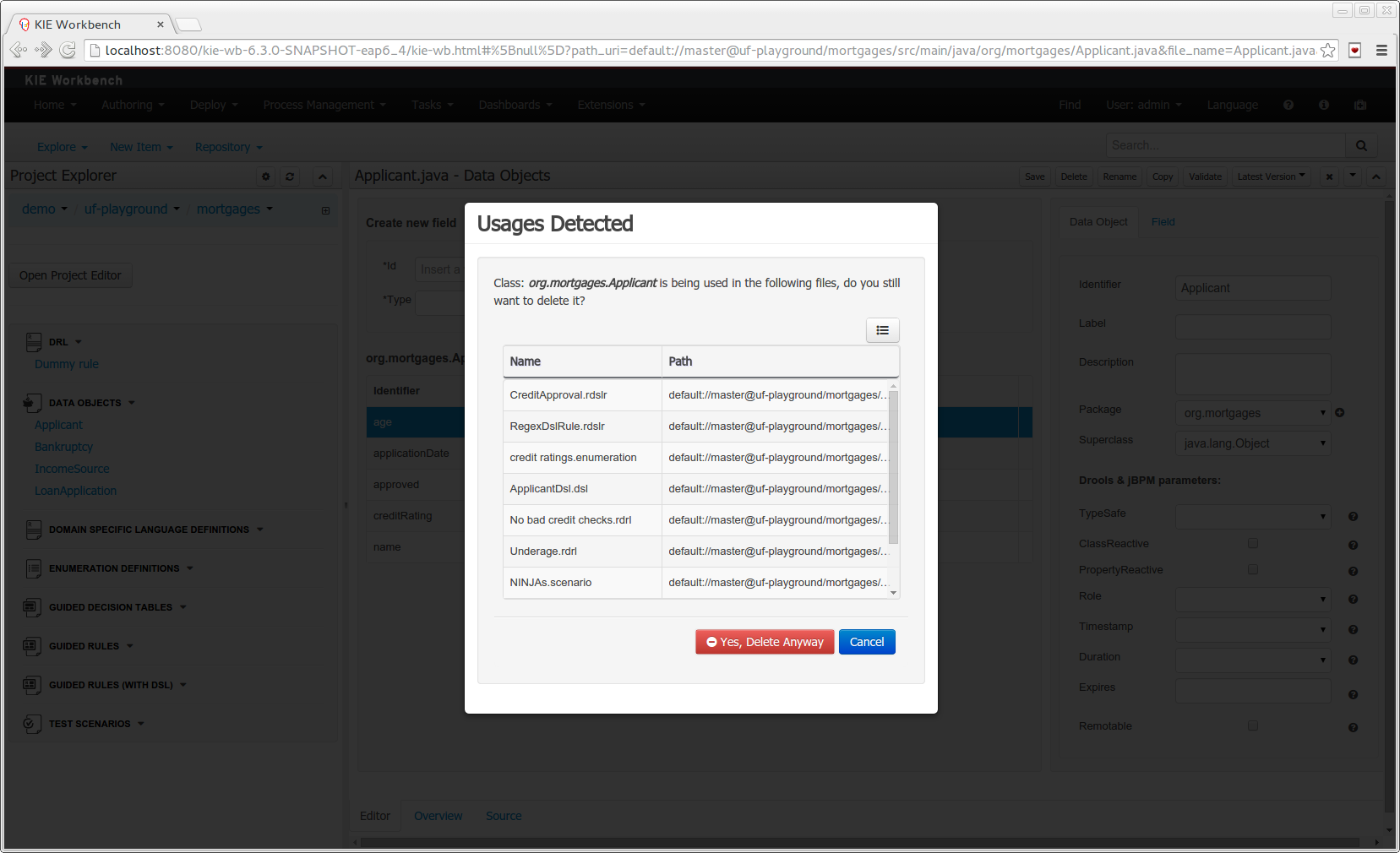
Class usages detection. Whenever a Data Object is about to be deleted or renamed, the project will be scanned for the class usages. If usages are found (e.g. in drl files, decision tables, etc.) the user will receive an alert. This will prevent the user from breaking the project build.
A new perspective called Management has been added under Servers top level menu. This perspective provides users the ability to manage multiple execution servers with multiple containers. Available features includes connect to already deployed execution servers; create new, start, stop, delete or upgrade containers.
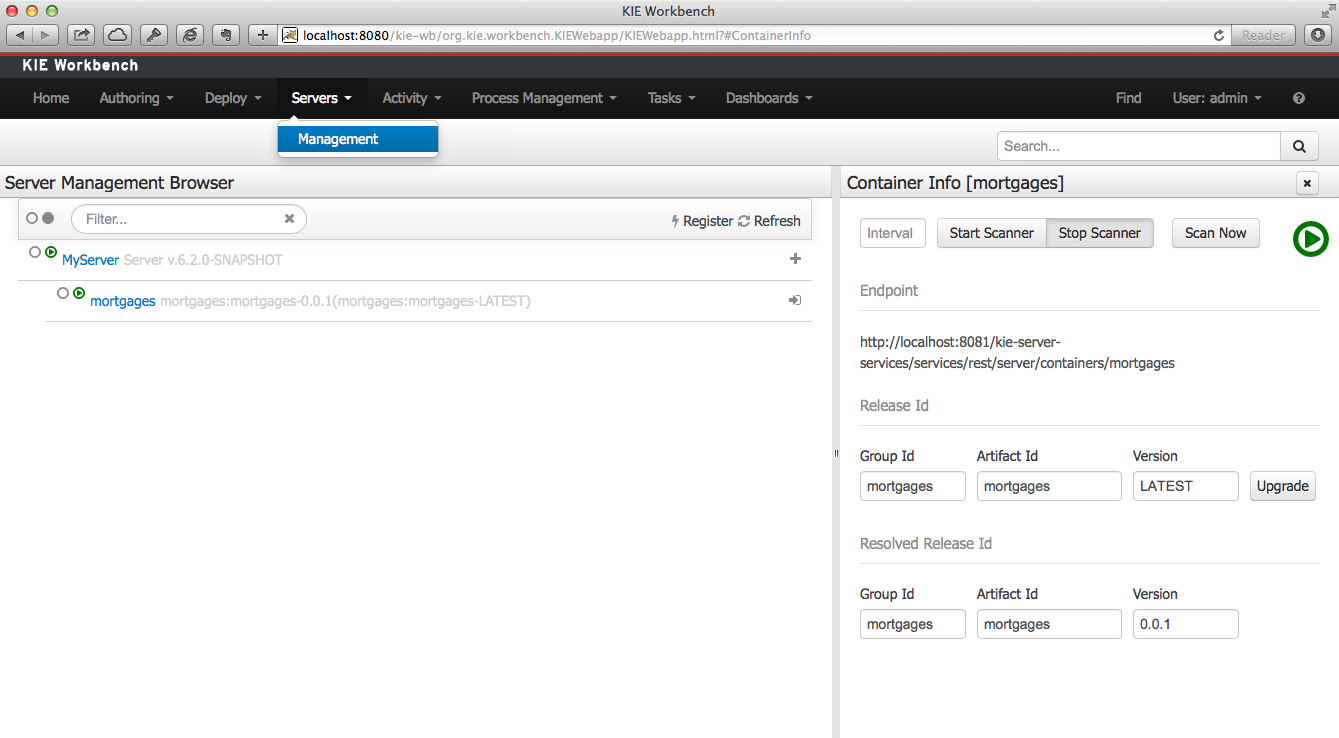
Note
Current version of Execution Server just supports rule based execution.
A brand new feature called Social Activities has been added under a new top level menu item group called Activity.
This new feature is divided in two different perspectives: Timeline Perspective and People Perspective.
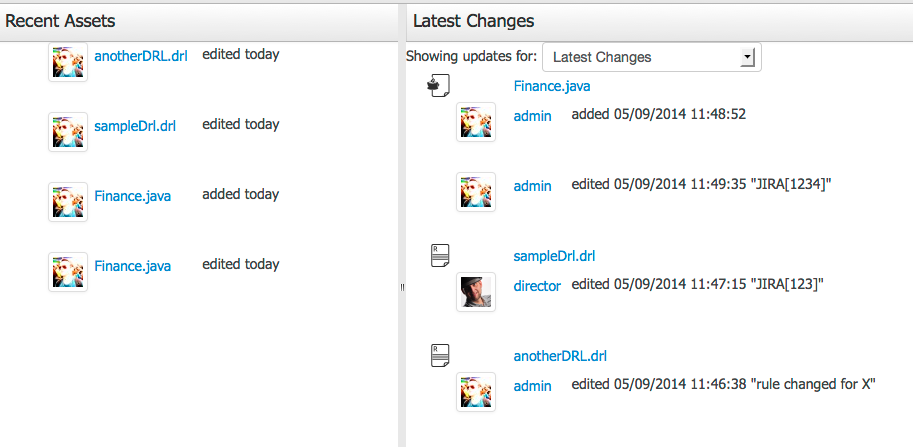
The Timeline Perspective shows on left side the recent assets created or edited by the logged user. In the main window there is the "Latest Changes" screen, showing all the recent updated assets and an option to filter the recent updates by repository.
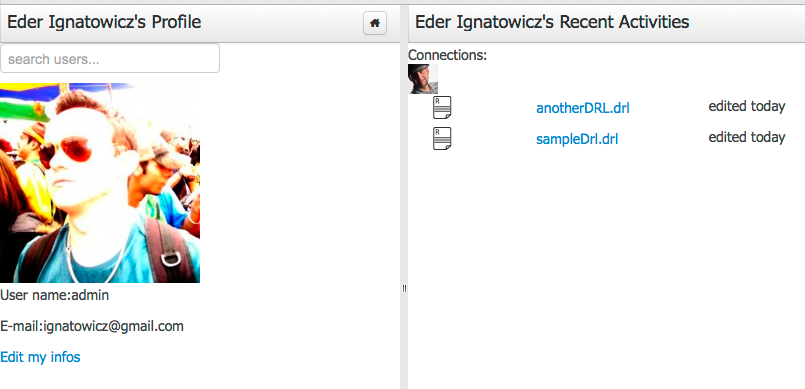
The People Perspective is the home page of an user. Showing his infos (including a gravatar picture from user e-mail), user connections (people that user follow) and user recent activities. There is also a way to edit an user info. The search suggestion can be used to navigate to a user profile, follow him and see his updates on your timeline.
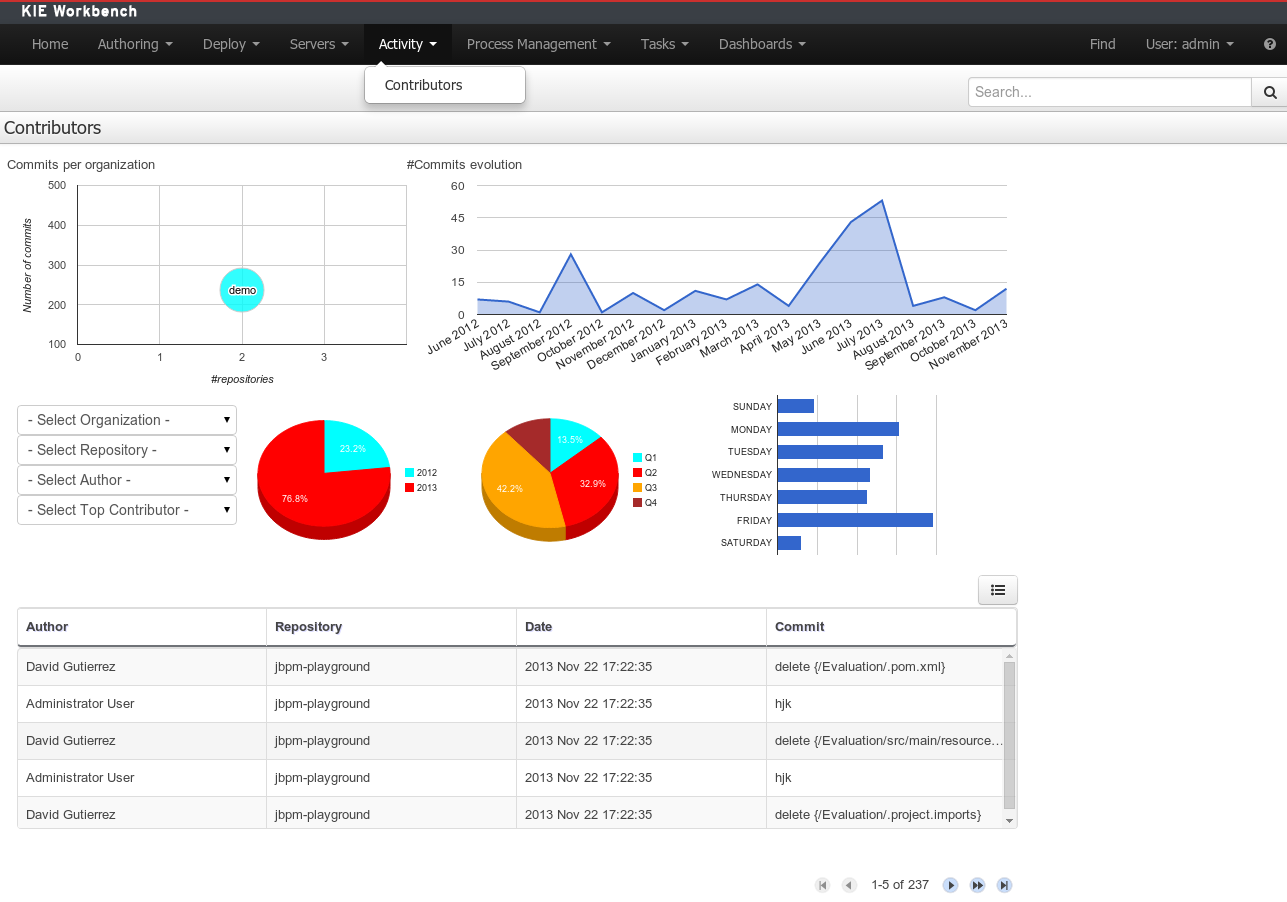
A brand new perspective called Contributors has been added under a new top level menu item group called Activity. The perspective itself is a dashboard which shows several indicators about the contributions made to the managed organizations / repositories within the workbench. Every time a organization/repository is added/removed from the workbench the dashboard itself is updated accordingly.
This new perspective allows for the monitoring of the underlying activity on the managed repositories.
The location of new assets whilst authoring was driven by the context of the Project Explorer.
This has been replaced with a Package Selector in the New Resource Popup.
The location defaults to the Project Explorer context but different packages can now be more easily chosen.
All Popups have been refactored to use GWT-Bootstrap widgets.
Whilst a simple change it brings greater visual consistency to the application as a whole.
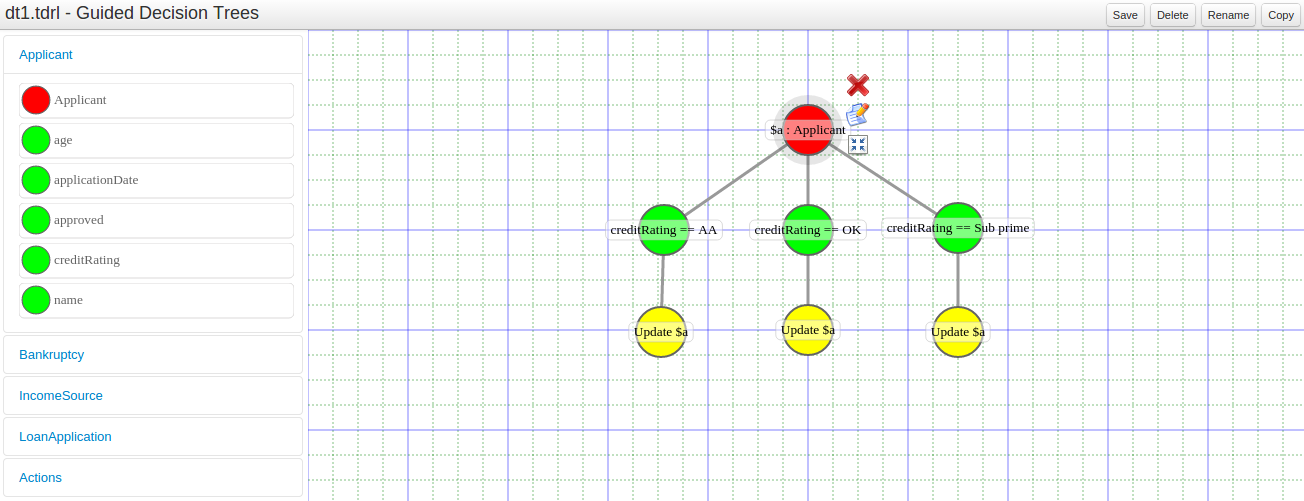
A new editor has been added to support modelling of simple decision trees.
See the applicable section within the User Guide for more information about usage.
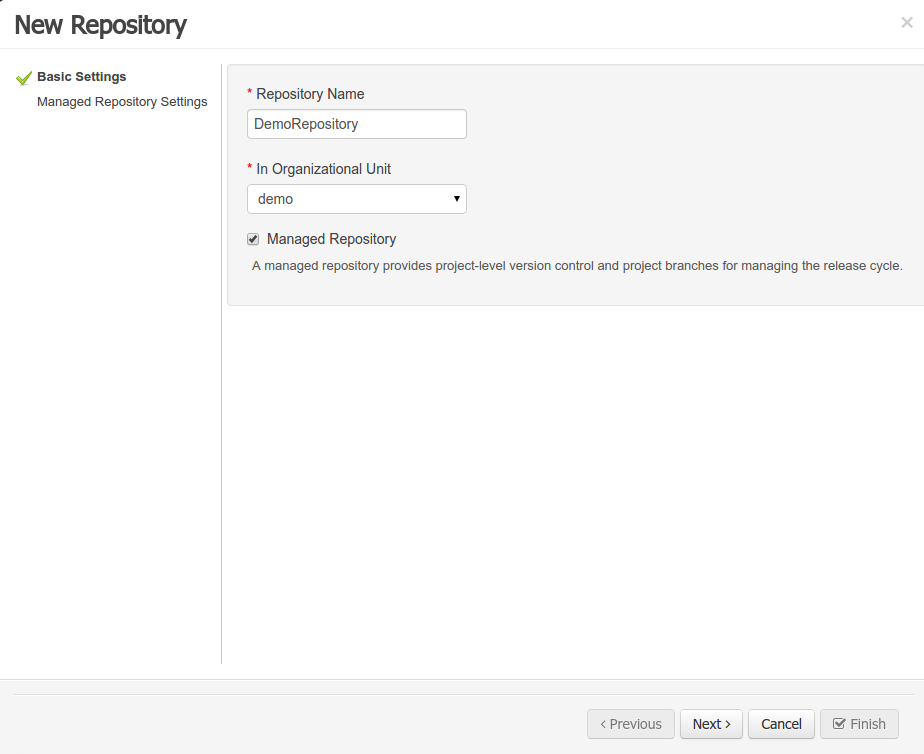
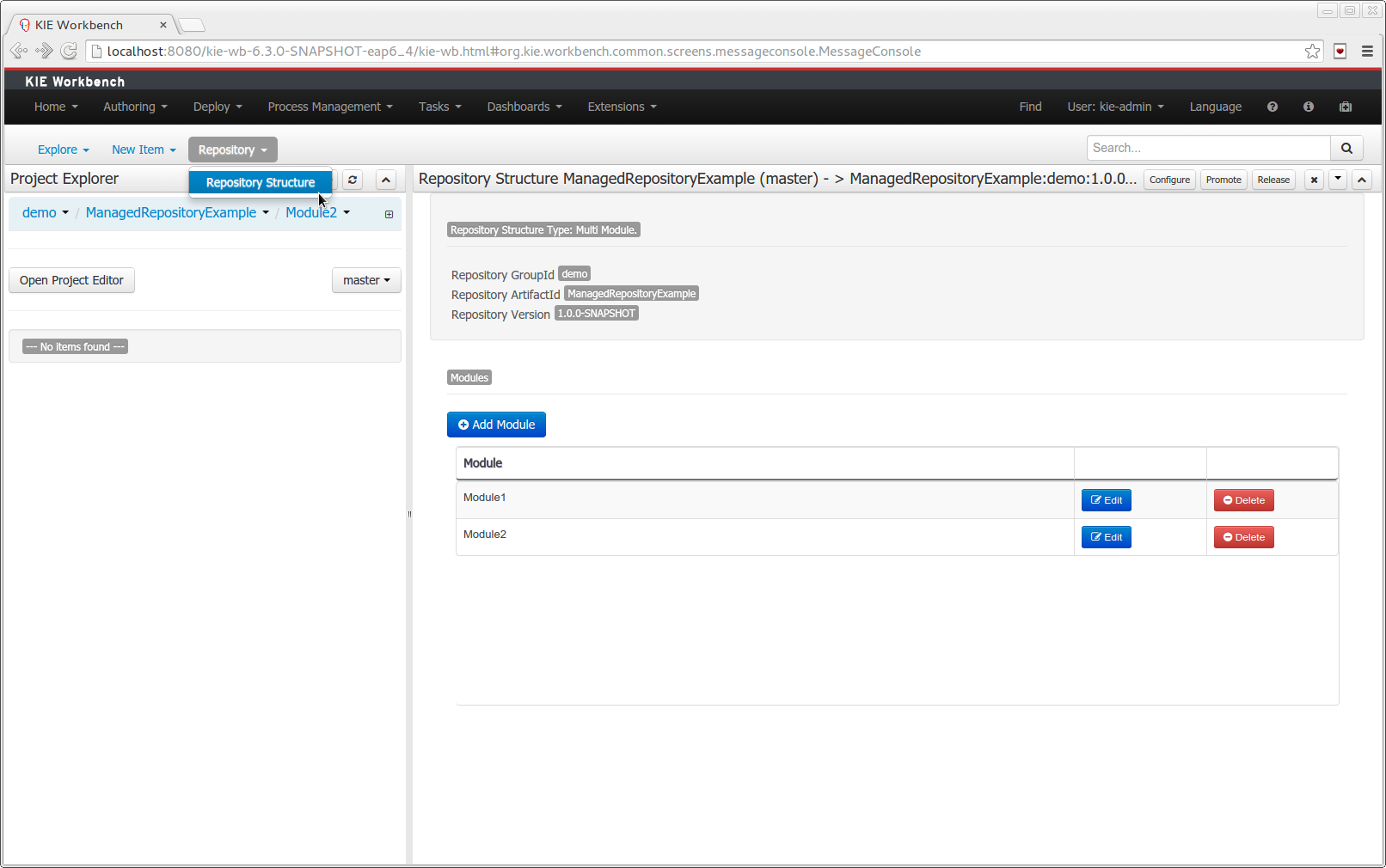
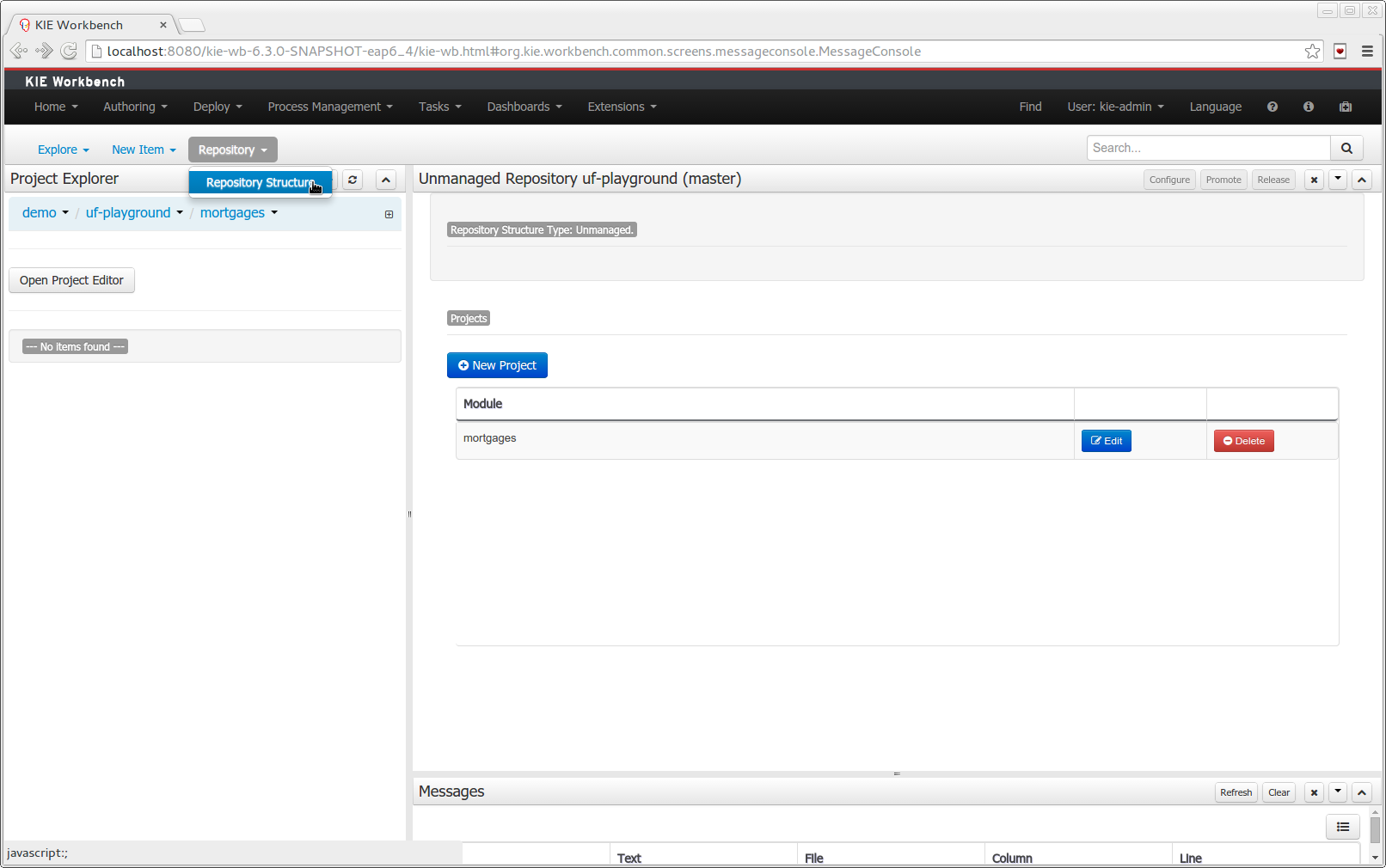
A wizard has been created to guide the repository creation process. Now the user can decide at repository creation time if it should be a managed or unmanaged repository and configure all related parameters.
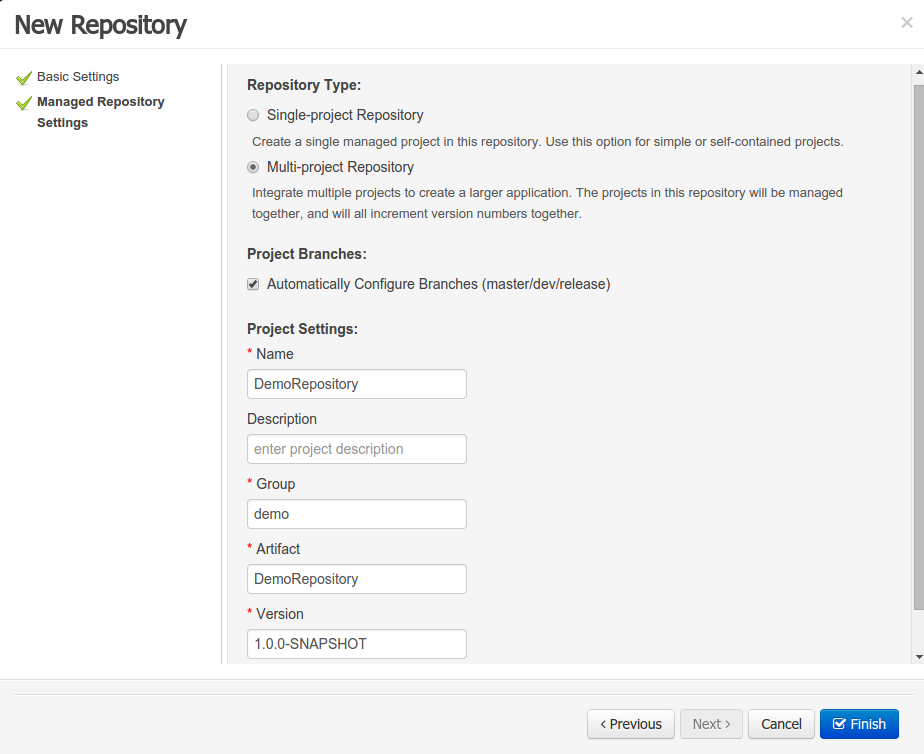
The new Repository Structure Screen will let users to manage the projects for a given repository, as well as other operations related to managed repositories like: branch creation, assets promotion and project release.
jBPM 6.1 comes with a ton of smaller improvements and bug fixes (done over the last few months on top of 6.0.1.Final), and also includes some important new features, adding to the foundation delivered as part of jBPM 6.0.
Now you can embed and run process/task forms that live inside the Kie-Workbench just adding a JavaScript library to your webapps. Look at the Using forms on client applications section to see the full functionality and usage examples.
Added new file type to manage upload documents on forms and store them on process variables. Using the Pluggable Variable Persistence you'll be able to create your own Marshalling Strategy and store the document contents on different systems (Database, Alfresco, Google Docs...) or use the default implementation and store them in your File System.
The execution server, that is part of the jbpm-console web tooling, now also comes with a Web Service interface (in addition to the existing REST, JMS and Java client interfaces).
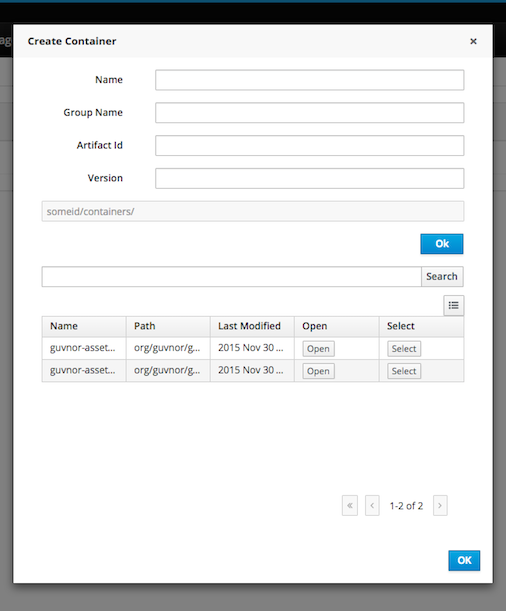
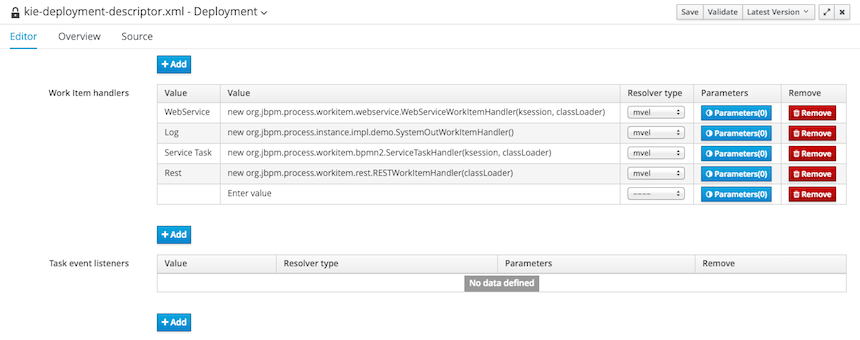
Deployment descriptors have been added as an optional, yet powerful way of configuring deployment units - kjars. Deployment descriptors allow to configure (among others)
persistence unit names
work item handlers
event listeners (process, agenda, task)
roles (for authorizarion - see section 1.5)
Deployment descriptors can be configured on various levels for enhanced flexibility to allow simple override functionality. Detailed definition of deployment descriptor can be found in section 14.1.1. Deployment descriptors
The process definition and process instance view in the jbpm console now also take the role-based access control restrictions into account that can be defined on the project the process is defined in. You can limit the visibility of a project (or repository as a whole) by associating some roles with it that are required to be able to see the project (or repository). This can be done when creating the repository, or bu using the command line interface to connect to the execution server. The deployment descriptor (see previous section) also allows you to further customize these roles at deployment time. At runtime, the views will check if the current logged in user has one of the necessary roles to be able to see that process. If not, the user will not see this process or process instance in the process definition or process instance list respectively.
The installer is updated to support:
Wildfly 8.1 as application server
Eclipse BPMN2 Modeler 1.0.2
Eclipse Kepler SR2
Spring integration has been improved to allow complete configuration of jBPM runtime using Spring XML. That essentially means there are number of factory beans provided as part of droolsjbpm-integration module that significanlty simplifies configuration of jBPM. Moreover it allows various configuration options such as:
reply on JTA and entity manager factory
rely on JTA and shared entity manager
rely on local transactions and entity manager factory
rely on local transactions and shared entity manager
Details about spring configuration can be found in this article.
Smaller enhancements also include:
Task service (query) improvements, significantly speeding up queries when you have a large numbers of tasks in the database.
Various improvements to the asynchronous job executor so it can handle larger loads more easily and can be configured (number of parallel threads executing the jobs, retries, etc.).
Ability to configure task administrator groups in a UserTask (similar to how you already could configure individual task administrators).
Removed limitation on custom implementations of work item handler, event listeners that had to be placed on global classpath - usually in jbpm-console.war/WEB-INF/lib. With that custom classes can be added as maven dependencies into the project and will be registered on underlying components (ksession).
Full round trip between Data modeler and Java source code is now supported. No matter where the Java code was generated (e.g. Eclipse, Data modeller), data modeler will only update the necessary code blocks to maintain the model updated.
New annotations @TypeSafe, @ClassReactive, @PropertyReactive, @Timestamp, @Duration and @Expires were added in order enrich current Drools annotations manged by the data modeler.
We have standardized the display of tabular data with a new table widget.
The new table supports the following features:
Selection of visible columns
Resizable columns
Moveable columns
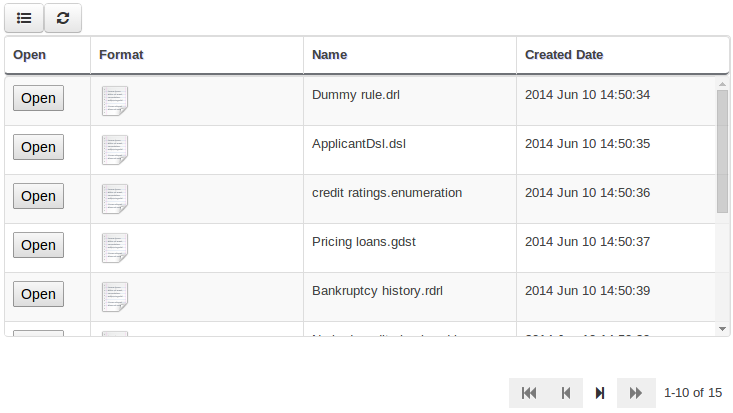
The table is used in the following scenarios:
Inbox (Incoming changes)
Inbox (Recently edited)
Inbox (Recently opened)
Project Problems summary
Artifact Repository browser
Project Editor Dependency grid
Project Editor KSession grid
Project Editor Work Item Handlers Configuration grid
Project Editor Listeners Configuration grid
Search Results grid
The Guided Rule Editor, Guided Template Editor and Guided Decision Table Editor have been
changed to generate modify(x){...}
Historically these editors supported the older update(x) syntax and hence
rules created within the Workbench would not respond correctly to
@PropertyReactive and associated annotations within a model. This has now been
rectified with the use of modify(x){...} blocks.
KIE is the new umbrella name used to group together our related projects; as the family continues to grow. KIE is also used for the generic parts of unified API; such as building, deploying and loading. This replaces the droolsjbpm and knowledge keywords that would have been used before.
One of the biggest complaints during the 5.x series was the lack of defined methodology for deployment. The mechanism used by Drools and jBPM was very flexible, but it was too flexible. A big focus for 6.0 was streamlining the build, deploy and loading (utilization) aspects of the system. Building and deploying activities are now aligned with Maven and Maven repositories. The utilization for loading rules and processess is now convention and configuration oriented, instead of programmatic, with sane defaults to minimise the configuration.
Projects can be built with Maven and installed to the local M2_REPO or remote Maven repositories. Maven is then used to declare and build the classpath of dependencies, for KIE to access.
The 'kmodule.xml' provides declarative configuration for KIE projects. Conventions and defaults are used to reduce the amount of configuration needed.
Example 25.1. Declare KieBases and KieSessions
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase1" packages="org.mypackages">
<ksession name="ksession1"/>
</kbase>
</kmodule>Example 25.2. Utilize the KieSession
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();It is possible to include all the KIE artifacts belonging to a KieBase into a second KieBase. This means that the second KieBase, in addition to all the rules, function and processes directly defined into it, will also contain the ones created in the included KieBase. This inclusion can be done declaratively in the kmodule.xml file
Example 25.3. Including a KieBase into another declaratively
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase2" includes="kbase1">
<ksession name="ksession2"/>
</kbase>
</kmodule>or programmatically using the KieModuleModel.
Example 25.4. Including a KieBase into another programmatically
KieModuleModel kmodule = KieServices.Factory.get().newKieModuleModel();
KieBaseModel kieBaseModel1 = kmodule.newKieBaseModel("KBase2").addInclude("KBase1");Any Maven produced JAR with a 'kmodule.xml' in it is considered a KieModule. This can be loaded from the classpath or dynamically at runtime from a Resource location. If the kie-ci dependency is on the classpath it embeds Maven and all resolving is done automatically using Maven and can access local or remote repositories. Settings.xml is obeyed for Maven configuration.
The KieContainer provides a runtime to utilize the KieModule, versioning is built in throughout, via Maven. Kie-ci will create a classpath dynamically from all the Maven declared dependencies for the artifact being loaded. Maven LATEST, SNAPSHOT, RELEASE and version ranges are supported.
Example 25.5. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.newKieContainer(
ks.newReleaseId("org.mygroup", "myartefact", "1.0") );
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();KieContainers can be dynamically updated to a specific version, and resolved through Maven if KIE-CI is on the classpath. For stateful KieSessions the existing sessions are incrementally updated.
Example 25.6. Dynamically Update - Java
KieContainer kContainer.updateToVersion(
ks.newReleaseId("org.mygroup", "myartefact", "1.1") );The KieScanner is a Maven-oriented replacement of the KnowledgeAgent
present in Drools 5. It continuously monitors your Maven repository
to check if a new release of a Kie project has been installed and if so, deploys it in
the KieContainer wrapping that project. The use of the KieScanner
requires kie-ci.jar to be on the classpath.
A KieScanner can be registered on a KieContainer
as in the following example.
Example 25.7. Registering and starting a KieScanner on a KieContainer
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0-SNAPSHOT" );
KieContainer kContainer = kieServices.newKieContainer( releaseId );
KieScanner kScanner = kieServices.newKieScanner( kContainer );
// Start the KieScanner polling the Maven repository every 10 seconds
kScanner.start( 10000L );In this example the KieScanner is configured to run with a fixed
time interval, but it is also possible to run it on demand by invoking the
scanNow() method on it. If the KieScanner finds, in the
Maven repository, an updated version of the Kie project used by that KieContainer
it automatically downloads the new version and triggers an incremental build of the new
project. From this moment all the new KieBases and KieSessions
created from that KieContainer will use the new project version.
The CompositeClassLoader is no longer used; as it was a constant source of performance problems and bugs. Traditional hierarchical classloaders are now used. The root classloader is at the KieContext level, with one child ClassLoader per namespace. This makes it cleaner to add and remove rules, but there can now be no referencing between namespaces in DRL files; i.e. functions can only be used by the namespaces that declared them. The recommendation is to use static Java methods in your project, which is visible to all namespaces; but those cannot (like other classes on the root KieContainer ClassLoader) be dynamically updated.
The 5.x API for building and running with Drools and jBPM is still available through Maven dependency "knowledge-api-legacy5-adapter". Because the nature of deployment has significantly changed in 6.0, it was not possible to provide an adapter bridge for the KnowledgeAgent. If any other methods are missing or problematic, please open a JIRA, and we'll fix for 6.1
While a lot of new documentation has been added for working with the new KIE API, the entire documentation has not yet been brought up to date. For this reason there will be continued references to old terminologies. Apologies in advance, and thank you for your patience. We hope those in the community will work with us to get the documentation updated throughout, for 6.1
A new public API has been created for interacting with the core engine (shared between jBPM and Drools). This not only handles runtime operations to start processes, etc. but also instantiating sessions, registering listeners, configuration, etc.
New APIs were added in various areas, like for example the TaskService interface was moved to the public API, the new RuntimeManager was introduced and a lot of related interfaces and classes were added as well.
For backwards compatibility with v5, a knowledge-api JAR has been constructed, that implements the old v5 knowledge-api interfaces on top of the v6 engine. Make sure to include this JAR in your classpath if you want to keep using the v5 API.
The execution engine itself has (mostly) remained the same, although we've done various improvements in the following areas:
RuntimeManager: instantiating a ksession (and an associated task service) has been simplified significantly, by introducing a runtime manager where you can simply ask for a reference to a ksession whenever you need it. The Runtime manager is responsible for initialization, configuration and disposal of the ksession (and task service), and three predefined strategies are available:
Singleton: the RuntimeManager reused the same ksession for all requests (and executes the requests in sequence, one at a time)
Session per request: the RuntimeManager instantiates a new ksession per request that will be used for executing that request and disposed at the end. Each request will receive its own ksession and they can all be executed in parallel.
Session per process instance: the RuntimeManager reuses the same ksession for all requests related to one specific process instance. This might be necessary if you are storing data inside your session (for example for rule evaluations) that you need to be available later in the process as well. Note that the session is disposed after each command but stored in the database so it can be restored whenever necessary.
jBPM Services (CDI): To simplify integration of jBPM inside CDI-based applications, the jbpm-services module contains various CDI services that you can configure and use inside your application simply by injecting the necessary services (like a RuntimeManager or TaskService for example) inside your application, making integration easier than ever.
Timer service: a Quartz-based timer service is now available, that allows you to dispose your session at any point in time, and the timer service will be responsible for rehydrating a ksession whenever a timer should be fired. This timer service also works in a clustered environment, where multiple nodes can work together on sharing the work load but timers will only be fired once by one of the nodes.
Exception and compensation management: various improvements in this area allow you to use more BPMN2 constructs related to exception and compensation management in your processes, and various strategies have been extended and documented to better handle exceptions in different ways.
Asynchronous handlers: asynchronous execution of interaction with external services can now be implemented by reusing the asynchronous job executor.
Asynchronous auditing using JMS: audit logging can now also be done asynchronously by sending the events to a JMS queue rather than persisting them as part of the engine transaction.
The task service has been refactored significantly as well, and the TaskService APIs have been moved to the public kie-api. Although the TaskService interfaces themselves haven't changed a lot, the internal implementation has been simplified. Auditing for the task-related operations (similar to the runtime engine auditing) has been added.
By default, a local task service will always be used by a ksession to perform various task-related operations (creating a task, being notified when a task is completed). Setting up a remote singleton task service and connecting multiple ksessions to this (using Mina or HornetQ) as was possible in jBPM5 is no longer possible, as it introduces more challenges that it brings advantages. Since the jBPM execution service now also provides a remote API for all task-related operations, we believe this setup is no longer necessary, and has been replaced by the use of a local task service in all use cases.
jBPM designer has been reimplemented and is fully integrated into the workbench. It now easily integrates with many of the workbench services available. In addition, the following features were added/improved on:
Improvement of jBPM Simulation engine and the UI. Added ability to specify simulation properties on more node type and added more results graphs such as the the Total Cost graph.
Many updates to the Designer Toolbar for usability purposes.
Visual Validation update - it now is a real-time visualization of issues done during process modeling.
Ability to generate task forms for specific task node.
Integration with the jBPM Form Modeler for both task and process forms.
Update to process properties - added grouping of properties into sections making it more user friendly to find properties.
Update to Object Library - added type specific tasks to palette (rather than having to morph to a certain type after adding a task to the canvas).
Save/Remove/CopyDelete feature have been added directly into Designer and integrate with the workbench services for those operations.
Autosave - option for users to enable auto-saving of their business process during modeling.
Two new default Service Tasks (REST and Web Services)
A new web-based data modeler is integrated in the workbench, which allows non-technical users to create data models (to be used in your processes and rules) in a user-friendly manner. These models are saved as Java classes (with the necessary annotations) in the project and added to the kjar upon build and deploy. Check the chapter on Data Modeler in the Workbench Part for all the details.
A new web-based form modeler is integrated in the workbench, which allows non-technical users to create forms (for starting processes and/or completing human task). The form modeler is a WYSIWYG editor where you can drag and drop form elements (text boxes, labels, etc.), link it to data that is expected as input or output of the form, customize properties of each element and the layout, etc. These forms are then shown when starting the process or completing a task, integrated into the appropriate runtime views. Check the chapter on Form Modeler in the Workbench Part for all the details.
The jBPM console has been reimplemented and is integrated into the workbench as well. It provides similar features as jBPM5 (starting process instances, inspecting current state and variables, looking at task lists) but is now much more powerful and exposes a lot more features. Check the chapter on Process and Task Management in the Workbench Part for all the details.
A new web-based monitoring and reporting tool has been integrated in the workbench. This displays charts, tables, etc. about the current status of your application(s). It comes with some process and task dashboards out-of-the-box (showing for example the number of running process instances, the number of tasks completed per time frame, etc.). These dashboards however can be fully customized to show the data that is relevant to you, including for example your own data sources, making domain-specific charts (for example showing your key performance indicators (KPIs) instead of generic process-related charts). Check the chapter on Business Activity Monitoring in the Workbench Part for all the details.
A workbench application, based on the UberFire framework, now unifies all web-based editors and tools into one large, configurable web application. It has many features, including:
Configurable workspace where you layout your own views by dragging and dropping
Unified login and role-based authentication, where what features you see depends on your role (admin, analyst, developer, user, manager, etc.).
A new home screen that will guide you through the life cycle of your business processes (authoring, deployment, execution, tasks and reporting).
Git-based repository that supports versioning and collaboration.
New project structure where artifacts (processes, rules, etc.) are combined into kjars (we removed the custom binary packages and replaced them with a normal JAR, containing the source artifacts) when a project is built. These kjars now also include not only processes and rules, but also forms, configuration files, data models (Java classes), etc. Kjars are Maven artefacts themselves (they have a group, id and version) and exposed as a Maven repository. When creating a ksession, Maven can be used to download the necessary kjars for your project from this Maven repository.
Sample
playgroundrepositories are (optionally) installed when starting up the workbench the first time, to get you started quickly with some predefined examples.
Check the Workbench Part for all the details.
The remote API has been redesigned and allows users to remotely connect to a running execution server and pass commands. The remote runtime API exposes (almost) the entire KieSession and TaskService API using REST or JMS, so commands can be sent to the remote execution server for processing and the results are returned. See the chapter on Business Activity Monitoring for all the details.
Guvnor also provides a REST API to access the various repositories, projects and artifacts inside these projects and manage and build them.
The workbench has had a big overhaul using a new base project called UberFire. UberFire is inspired by Eclipse and provides a clean, extensible and flexible framework for the workbench. The end result is not only a richer experience for our end users, but we can now develop more rapidly with a clean component based architecture. If you like he Workbench experience you can use UberFire today to build your own web based dashboard and console efforts.
As well as the move to a UberFire the other biggest change is the move from JCR to Git; there is an utility project to help with migration. Git is the most scalable and powerful source repository bar none. JGit provides a solid OSS implementation for Git. This addresses the continued performance problems with the various JCR implementations, which would slow down once the number of files and number of versions become too high. There has been a big "low tech" drive, to remove complexity. Everything is now stored as a file, including meta data. The database is only there to provide fast indexing and search. So importing and exporting is all standard Git and external sites, like GitHub, can be used to exchange repositories.
In 5.x developers would work with their own source repository and then push JCR, via the team provider. This team provider was not full featured and not available outside Eclipse. Git enables our repository to work any existing Git tool or team provider. While not yet supported in the UI, this will be added over time, it is possible to connect to the repo and tag and branch and restore things.
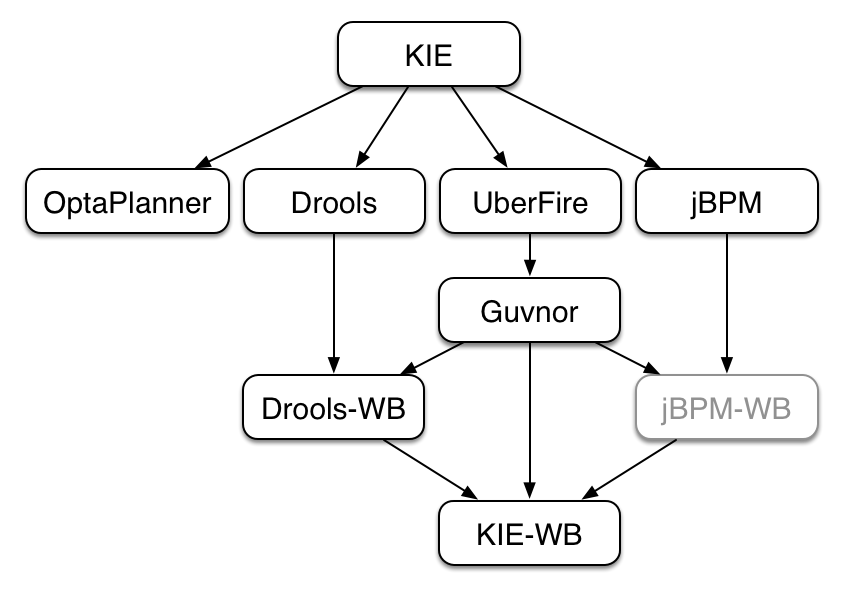
The Guvnor brand leaked too much from its intended role; such as the authoring metaphors, like Decision Tables, being considered Guvnor components instead of Drools components. This wasn't helped by the monolithic projects structure used in 5.x for Guvnor. In 6.0 Guvnor 's focus has been narrowed to encapsulates the set of UberFire plugins that provide the basis for building a web based IDE. Such as Maven integration for building and deploying, management of Maven repositories and activity notifications via inboxes. Drools and jBPM build workbench distributions using Uberfire as the base and including a set of plugins, such as Guvnor, along with their own plugins for things like decision tables, guided editors, BPMN2 designer, human tasks.
The "Model Structure" diagram outlines the new project anatomy. The Drools workbench is called KIE-Drools-WB. KIE-WB is the uber workbench that combines all the Guvnor, Drools and jBPM plugins. The jBPM-WB is ghosted out, as it doesn't actually exist, being made redundant by KIE-WB.
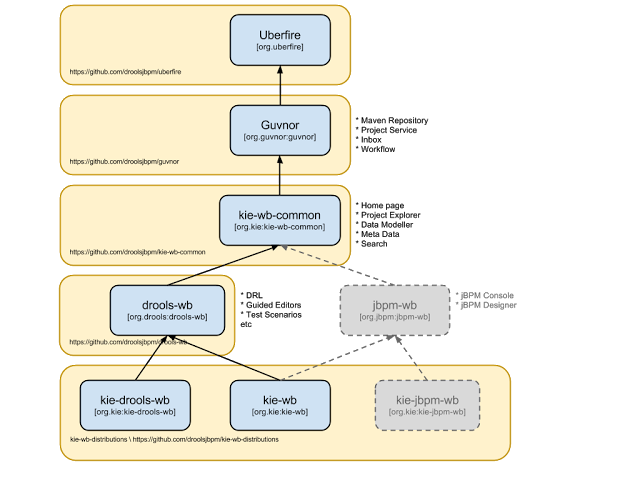
Important
KIE Drools Workbench and KIE Workbench share a common set of components for generic workbench functionality such as Project navigation, Project definitions, Maven based Projects, Maven Artifact Repository. These common features are described in more detail throughout this documentation.
The two primary distributions consist of:
KIE Drools Workbench
Drools Editors, for rules and supporting assets.
jBPM Designer, for Rule Flow and supporting assets.
KIE Workbench
Drools Editors, for rules and supporting assets.
jBPM Designer, for BPMN2 and supporting assets.
jBPM Console, runtime and Human Task support.
jBPM Form Builder.
BAM.
Workbench highlights:
New flexible Workbench environment, with perspectives and panels.
New packaging and build system following KIE API.
Maven based projects.
Maven Artifact Repository replaces Global Area, with full dependency support.
New Data Modeller replaces the declarative Fact Model Editor; bringing authoring of Java classes to the authoring environment. Java classes are packaged into the project and can be used within rules, processes etc and externally in your own applications.
Virtual File System replaces JCR with a default Git based implementation.
Default Git based implementation supports remote operations.
External modifications appear within the Workbench.
Incremental Build system showing, near real-time validation results of your project and assets.
The editors themselves are largely unchanged; however of note imports have moved from the package definition to individual editors so you need only import types used for an asset and not the package as a whole.
CDI is now tightly integrated into the KIE API. It can be used to inject versioned KieSession and KieBases.
Figure 25.63. Side by side version loading for 'jar1.KBase1' KieBase
@Inject
@KSession("kbase1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.0")
private KieBase kbase1v10;
@Inject
@KBase("kbase1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.1")
private KieBase kbase1v10;Figure 25.64. Side by side version loading for 'jar1.KBase1' KieBase
@Inject
@KSession("ksession1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.0")
private KieSession ksessionv10;
@Inject
@KSession("ksession1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.1")
private KieSession ksessionv11;Spring has been revamped and now integrated with KIE. Spring can replace the 'kmodule.xml' with a more powerful spring version. The aim is for consistency with kmodule.xml
Aries blueprints is now also supported, and follows the work done for spring. The aim is for consistency with spring and kmodule.xml